The Importance Of Pipes
There’s a very subtle, often overlooked thing in Unix, the pipeline, or | character (often just called a pipe).
This is perhaps the most important thing in the entire operating system, with the possible exception of the “everything is a file” concept.
In case you’re unfamiliar (or didn’t feel like reading the wiki page above), here’s the basic concept:
A pipe allows you to link the output of one program to the input of another.
eg foo | bar – this takes the output from foo, and feeds whatever-it-is into bar – rather than, say, having to point bar at a specific file to make it do anything useful.
Why are pipes so awesome?
Well, the following reasons:
- Each program only has to do one thing, & do it well
- As such, development of those programs can be split up – even to the point where a thousand people can independently write a thousand programs, & they’ll all still be useful
- Each of those programs is very simple, thus faster to develop, easier to debug, etc
- Extremely complex behaviour can be created by linking different programs together in different ways
- None of that higher level behaviour has to be pre-thought or designed for
So, Unix has ended up with a ton of small but powerful programs. For example:
- ls – lists a directory
- cat – displays stuff
- sort – sorts stuff
- grep – finds things in stuff
- tr – translates stuff (eg, upper to lower case)
- wc – counts words or lines
- less – pauses stuff, allowing forwards & backwards scrolling
I’ve been deliberately vague with the descriptions. Why? Because ‘stuff’ can mean a file – if we specify it, or, it can mean whatever we pass in by putting a pipe in front of it.
So here’s an example. The file we’ll use is /usr/share/dict/words – ie, the dictionary.
cat /usr/share/dict/words
displays the dictionary
cat /usr/share/dict/words | grep eft
displays dict, but only shows words with ‘eft’ in them
cat /usr/share/dict/words | grep eft | sort
displays ‘eft’ words, sorted
cat /usr/share/dict/words | grep eft | sort | less
displays sorted ‘eft’ words, but paused so we can see what the hell we’ve got before it scrolls madly off the screen
cat /usr/share/dict/words | grep eft | grep -ve ‘^[A-Z]’ | sort | less
displays paused sorted ‘eft’ words, but removes any that start with capital letters (ie, all the Proper Nouns)
cat /usr/share/dict/words | grep eft | grep -ve ‘^[A-Z]’ | wc -l
gives us the count of how many non proper-noun ‘eft’ words there are in the dictionary (in the huge british english dictionary? 149, since I know you’re curious)
So there’s an additional benefit which is probably obvious. Debugging a complex set of interactions with pipes is incredibly straightforward. You can simply build up what you think you need, experimenting a little at each stage, & viewing the output. When it looks like what you want, you just remove the output-to-screen, and voila!
For the end-users, this means that the operating cost of using the system in a complex manner is drastically reduced.
What would happen without pipes? You’d end up with monolithic programs for every imaginable combination of user need. Ie, an unmitigated disaster. You can see elements of this in, umm, ‘certain other’ operating systems. *cough*
Most importantly of all, there is a meta benefit. A combination of all of the above benefits.
Pipes enable incredibly complex higher level behaviours to emerge without being designed in. It’s a spontaneous emergent behaviour of the system. There’s no onus on the system development programmers to be demi-gods, all they need to do is tackle one simple problem at a time – display a file, sort a file, and so on. The system as a whole benefits exponentially from every small piece of added functionality, as pipes then enable them to be used in every possible permutation.
It’s as if an anthill full of differently talented ants was suddenly building space ships.
Perhaps a better bits-vs-atoms metaphor is of money. Specifically the exchange of goods (atoms) for money, allows the conversion of those atoms into other atoms, via money. In the same way, pipes allows different programs to seamlessly interact via streamed data, in infinitely variable ways.
You don’t need to know how to make a car, since you can do what you’re good at, get paid, & exchange that money for a car. Or a boat. Or a computer. Society as a whole is vastly better off as each person can specialize & everybody benefits. Think how basic our world would be if we only had things that everybody knew how to build or do. Same thing with computers & pipes.
What seems like an almost ridiculously simple concept, pipes, has allowed an unimaginably sophisticated system to emerge from simple, relatively easily built pieces.
It’s not quite the holy grail of systems design, but it’s bloody close.
related
A Nifty Non-Replacing Selection Algorithm
Algorithms are awesome fun, so I was super pleased when my little bro asked me to help him with a toy problem he had.
The description is this: It’s a secret santa chooser. A group of people, where each person has to be matched up with one other person, but not themselves.
He’s setup an array that has an id for each person.
His initial shot was something like this (pseudo, obviously):
foreach $array as $key => $subarr {
do {
// $count is set to count($array)
$var = rand(0, $count)
} while $var != $key and $var isn't already assigned
$array[$key][$assign] = $var
}
Initially he was mostly concerned that rand would get called a lot of times (it’s inefficient in the language he’s using).
However, there’s a ton of neat (non-obvious) problems with this algorithm:
- By the time we’re trying to match the last person, we’ll be calling rand (on average) N-1 times
- As a result, it’s inefficient as hell ( O(3N+1)/2)? )
- There is a small chance that on the last call we’ll actually lock – since we won’t have a non-dupe to match with
- Not obvious above, but he also considered recreating the array on every iteration of the loop *wince*
Add to this some interesting aspects of the language – immutable arrays (ie, there’s no inbuilt linked lists, so you can’t del from the middle of an array/list) & it becomes an interesting problem.
The key trick was to have two arrays:
One, 2-dimensional array (first dim holding keys, second the matches)
and one 1-dimensional array (which will only hold keys, in order).
Let’s call the first one “$list” and the second “$valid”.
The trick is this – $valid holds a list of all remaining valid keys, in the first N positions of the array, where initially N = $valid length. Both $list & $valid are initially loaded with all keys, in order.
So, to pick a valid key, we just select $valid[rand(N)] and make sure it’s not equal to the key we’re assigning to.
Then, we do two things:
- Swap the item at position rand(N) (which we just selected) with the Nth item in the $valid array, &
- Decrement N ($key_to_process).
This has the neat effect of ensuring that the item we just selected is always at position N+1. So, next time we rand(N), since N is now one smaller, we can be sure it’s impossible to re-select the just selected item.
Put another way, by the time we finish, $valid will still hold all the keys, just in reverse order that we selected them.
It also means we don’t have to do any array creation. There’s still a 1/N chance that we’ll self-select of course, but there’s no simple way of avoiding that.
Note that below we don’t do the swap (since really, why bother with two extra lines of code?) we simply ensure that position rand(N) (ie, $key_no) now holds the key we didn’t select – ie, the one that is just off the top of the selectable area.
Oh, and in this rand implementation rand(0, N) includes both 0 AND N (most only go 0->N-1 inclusive).
$valid = array_keys($list);
$key_to_process = count($valid) - 1;
do {
$key_no = rand(0, $key_to_process);
if ($key_to_process != $valid[$key_no]) {
$list[$key_to_process][2] = $valid[$key_no];
$valid[$key_no] = $valid[$key_to_process];
$key_to_process--;
}
# deal with the horrid edge case where the last
# $list key is equal to the last available
# $valid key
if ($key_to_process == 0 and $valid[0] == 0) {
$key_no = rand(1, count($list) - 1);
$list[0][2] = $key_no;
$list[$key_no][2] = 0;
$key_to_process--;
}
} while ($key_to_process >= 0);
Without the edge-case code, this results in a super fast, nice slick little 10 or so line algorithm (depending on how/if you count {}’s :)
Elegant, I dig it.
related
13.Dec.2008Adobe AIR Locks If Installer Service Not Running
This is kindofa ridiculous post, but I Googled & couldn’t find anything, so this is primarily to help other people that might have this problem.
Adobe AIR apps will lock up (ie freeze) if you try to click a url (http link) in them and the Windows Installer service isn’t running.
I tested this with both in Twhirl (v 0.8.6 & 0.8.7) & Tweetdeck (v0.20b), on Windows 2000 (Win2k) SP4.
Typically if you start the service (either through the gui interface, or with a NET START MSISERVER run at dos or from Start-Run) after you’ve clicked a link, it’ll unlock the app.. but not always.
I have no idea why AIR needs to have the installer service running in order for it to connect to your browser (frankly I find it both suspicious & more than a little lame), but there we have it.
Hopefully this helps someone. And yes, this was a deliberately keyword heavy post :)
related
20.Nov.2008Auto Responders Are Good, Yes?
I recently had a very simple task – I wanted to get one of my brokers to send my daily account mails to a different email account.
That should be straight forward enough, right? Click the subscription information link, enter a new address, and on with my day?
Wooah Nelly, slow down there.
Some immediate problems:
- The email is completely blank, with a large attached pdf. That’s all, which means:
- No href links of ANY kind in the email, oh and:
- The one url in the pdf doesn’t match the ‘from’ domain
- This is a long dormant account, at a company that has been bought out three times since I last used it – so I have no phone contact information for them either (yes, I have tried to get them to only send me the monthly update, but they insist on their 30 identical dailies – but that’s a post for another time)
So, try the obvious – hit reply & request a change.
After two weeks of trying that, time for a new tack. I go to the website listed – a completely different company (it looks like they’ve outsourced their email blasting, which might explain their lack of flexibility) – pick the most likely looking email address I can find, and write a polite email.
A week later, still no response. Still getting these more or less useless (but oversized) emails to the wrong account.
So, time for a more aggressive approach. I go to the whois registry & get tech & biz contacts. I go to all the related websites. I get EVERY public email address I can find, and mail them all.
There’s seventeen of them.
I am polite – I explain that I realise I’m probably (after all, ONE of them may be the right one so I can’t be 100% certain) emailing the wrong person, but if they could please forward it on.. yadda yadda yadda.
I may have also *cough*accidentally*cough* mentioned that the CAN-Spam Act 2003 (yes, it’s an American company) makes it a legal requirement that there be working unsubscribe links available.
The fact that I’m emailing vice presidents & CEO’s in five countries I’m less concerned with – if they don’t hear about it, how will this ridiculously trivial problem ever get corrected? I don’t play golf with any of these guys.
Frankly I’m amazed that any company has public (& clickable, ie mailto) email addresses on the web considering how bad spam is these days – let alone vaguely high level people, but hey.
I get 7 responses, one justifiably aggrieved at being distracted from their Very Important Job. Mostly helpful, one super helpful who finally gets the job done.
And three bounces.
The only thing worse than posting email addresses publically is posting dead email addresses. Way to misunderestimate the web, guys.
But then, I’m guessing if they really ‘got’ the internet, they’d also have an auto-responder by now.
related
12.Nov.2008Old School Cool
Holey Moley this is so many flavours of cool I just had to post it:
I mean really, what’s not to like about that?
related
16.Sep.2008The Trouble With Ratios
Ratios are used all over the place. No huge surprise there – they are, after all, just one number divided by another.
The well known problem case is when the denominator (the bottom bit) is zero, or very near zero. However, there are other subtler issues to consider.
Here’s a chart that has a ratio as the X axis:
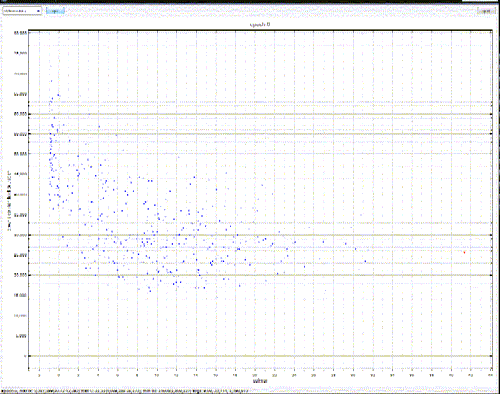
Don’t sweat the details, they’re not terribly important – just the rough distribution.
The X axis in this case is what’s called a Calmar – ie, the total dollar return of a system divided by it’s maximum drawdown. Or, in English – how much you make proportional to how big your pockets need to be. This gives a non-dollar based (ie, “pure”) number that can then be compared across markets, systems, products, whatever.
This graph is actually a bit trickier than that, since there’s actually 3 dimensions of data there – it’s just the third dimension isn’t plotted – but we’ll get back to that.
Where this gets ugly is when, in the case of the Calmar above, the drawdown drops to, or near to, zero. For example, if you have a system that only trades once – and it’s a winning trade – the calmar will be very, very large. Even if you chuck out systems that are obviously a bit nutty like that, you can still end up with situations where the ratio has just blown out of all proportion.
Which results in this:
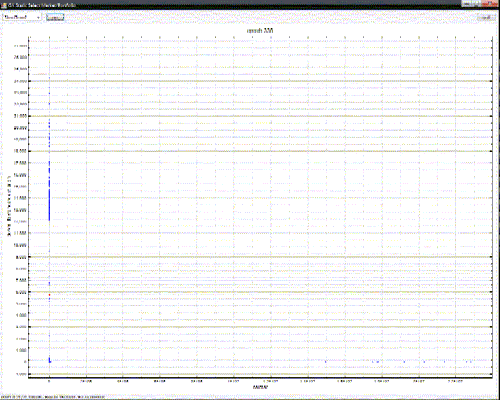
See how everything is in a vertical line on the left?
Well, it’s not. Those points are actually quite well spread out – it’s just that instead of the X axis going from 0->50 as in the first case, it now goes from 0->22 million – of which only a small number are greater than a hundred (you can see them spread out on the right, very close to the Y axis)
In this example, we can see the problem, so we’re aware of it. However, what if the ratio had been the unplotted third dimension? We might never have known.
Now, the way that I’m using these ratios internally, I’m protected from these sorts of blowouts – I simply compare sets of ratios. If one is bigger, it doesn’t matter if it’s bigger by 2 or by 2 billion.
However, there are many situations where you might want proportional representation. If one value is twice as big, say, it should occur twice as often. In this case, ratios that explode out by orders of magnitudes quickly swamp results, and drive the whole thing into the ground.
You swiftly end up with a monoculture. One result eats all the others, and instead of a room full of happy spiders doing their thing, you end up with one fat angry spider in the middle of the room. Umm, so to speak.
Ratios can be dangerous, kids. Watch out!
related
02.Aug.2008Cuil Really Isn’t (Yet)
There’s been a lot of grumping about Cuil lately, so I thought I’d add to it (hopefully in interesting new ways).
I’ll talk in context of a site that I have *cough* some familiarity with: galadarling.com (hint: I built & managed it for the last two years). This site gets over 100k uniques a week, has a google pagerank of 6, and a technorati rank in the mid 5000’s. I.e., it’s not Yahoo, but it is a significant, popular smaller site.
The obvious test – surely searching for gala darling would return the site? It’s not complicated. Her name is the url. But no:
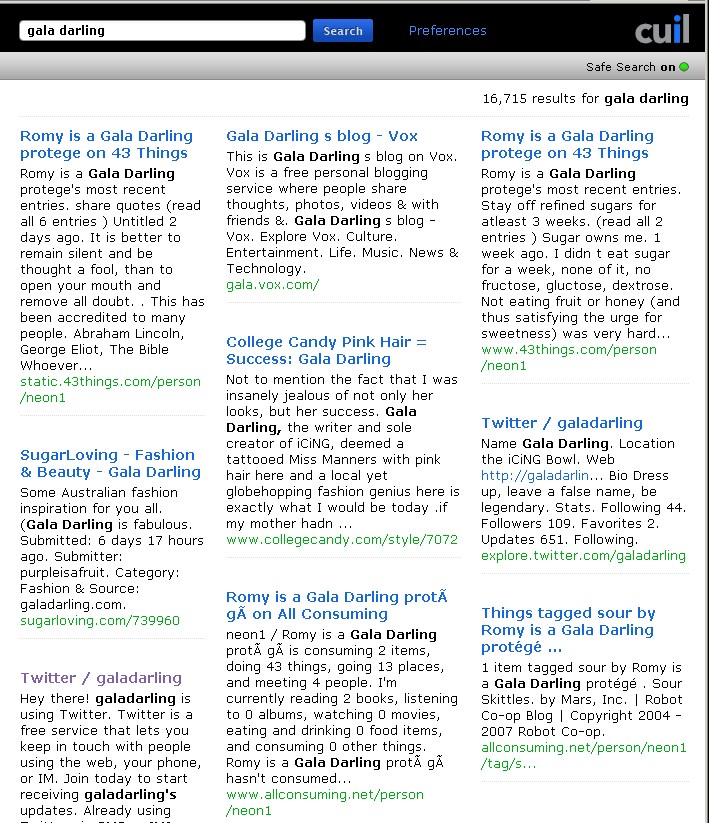 (click for a clearer view)
(click for a clearer view)Maybe it’s the safe search? No, flick that off, and exactly the same results:
 (click for a clearer view)
(click for a clearer view)Putting in “gala darling” in quotes (just like that) results in the exact same result set. Huh?
Even scarier, putting in galadarling (all one word) doesn’t even return the site. How is this possible?
Even worse than that – gala.vox.com is the second returned result. This is a single page that was setup once and then ignored. It’s not just not finding the correct result, it’s actively returning junk.
None of these sets include Gala’s livejournal, which is updated every couple of weeks, let alone the actual site that has her name on it.
With the exception of her twitter account, all the results on the front page are other sites, talking about her… and this is useful.. how?
I looked at the first 20 pages of results – couldn’t find either her livejournal or main site. vox.com somehow managed to get several hundred mentions. A single collegecandy page appeared at least 5 times.
Ok, it’s common knowledge that the Cuil results are crap. How about some other things.
- When you first load the page, you have to actually click to get into the textbox to enter your search terms.
- For some reason I’m asked to accept cookies both from cuil.com (fair enough), and cuilimg.com (what? why?)
- When paging through the results, there’s no way to go back to the start, as once you get past page 10, the earlier pages scroll off to the left, so you have to go backwards in chunks of 4 or 5.
- There’s no way to get more results on a screen. Even on my 1900 pixel wide screen & a tiny font, I still only get 10ish results per page. Google allows me 100 – why should I click-wait-click-wait just to use Cuil?
To their credit, Cuil’s bot is not hitting the site anywhere near as much as it used to, so that’s one good thing. Considering galadarling is updated typically once a day, plus maybe a hundred comments, the Cuil bot (twiceler) used to hit the site about a thousand times a day (resulting in it getting blocked by damn near everyone). For comparison, Google’s bots hit it 400 times a day (partly that will be because there is context-sensitive advertising on the site, so Google needs to scan for that). Now Twiceler is visiting about a hundred times a day – much more reasonable given the update frequency.
I’ve talked to the guys running Cuil (back when it still had two ‘l’s in its name). They’re obviously very smart cookies and they definitely care about what they do. If they can shake Google up – well, great – and I say that as a Google shareholder. They definitely have a lot of bugs to iron out though, and the reliability of those results needs to be right at the top of the list. Without trust, what do they have?
related
14.Jul.2008The Next Generation of Neural Networks
Given that I spent five+ years of my life in the early 90’s doing nothing but eat, drink & dream neural networks, this Google talk by Geoffrey Hinton (one of the giants of nnets) was one of the most stimulating, exciting & thought provoking things I’ve ever seen. Plus he seems like a hell of a nice guy – has a great sense of humour.
It’s an hour long, but well worth allocating the time to watch. [No embed available, unfortunately]
If you’re in a rush, here’s the key bit: 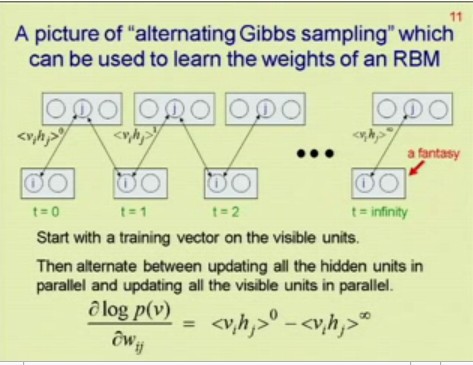
You’re very welcome. No need to thank me :)
It is, however, singularly awesome – took him 17 years to figure out, so appreciate it, damn it!
related
02.Jul.2008Unit Testing – Necessary, but Not Enough
I realised recently that I’d hit a point of diminishing returns. My overall code base was now so complex that any change I introduced in certain areas was taking exponentially longer to debug & ensure accuracy.
Of course, I had a test rig – otherwise how would I know what I was doing was correct in the first place?
The central core of all my systems is a rebuild of a now antiquated black box trading platform. I don’t have the source, but I need to duplicate the behaviour.
The test rig is pretty sophisticated – it didn’t start that way, and it shouldn’t really have needed to be, buuuuut
The old system:
1. Calculates using single precision floating point math.
If I need to explain why this is painful, check this out – if even the guys running Excel get occasionally tripped up by floating point math, what hope is there for the rest of us? Single point means there’s only half as many bits (32) to do maths in vs the default double (64 bits). Rough shorthand, single precision gives you get 6 decimal places. A number like ‘12000.25’, you’ll lose the ‘5’. If it’s negative, you’ll lose the ‘.25’. This means lots of rounding errors, and the more calculations you do, the more errors. The systems I’m working with do a LOT of calculations.
2. Rounds incoming numbers non deterministically
Mostly you can guess correctly what it’s going to decide a market price becomes, but particularly with markets that move in 1/32’s or 1/64 (ie, not simple decimals), this rounding becomes arbitrary if not damn ornery (rounded? no. up? no. down? no. truncated? no. based on equivalent string length? maybe)
3. Makes ‘interesting’ assumptions
Things like the order that prices get hit, how numbers are calculated internally (eg X = function(A/B) often returns a different result from Y = A/B; X = function(Y), that slippage only occurs in some situations and not others, and so on. Some make sense, in a way, many we don’t want. So now we have two modes of operation “old, broken, compatible, testable” and “new, not-broken, different numbers, untestable”
4. Has ‘chains’ of internal dependencies.
So, unsurprisingly, any of the above errors will then cascade through the output, fundamentally changing large chunks of the results.
So, the test rig allows for all this. Understands where common rounding problems occur, and how they cascade. Sorts by seriousness of the discrepencies, and so forth. Oh, and it does this by automatically tracking 60 or 70 internal variables for each calculation set across 7000 days on 60 markets. Ie, filtering & matching its way through 20-30 million data points.
But this still isn’t enough.
And this is where I see the light, and realise that this unit testing stuff that people have been raving about might actually be useful. So far, it has been. It’s enabled me to auto-scan a ton of possible problems, keep things in alignment as the system adjusts to changing requirements – all the palava you’ve read about.
But I’ve been thinking. No amount of unit testing would catch the errors my test rig will. Not that the rig is that amazing – just that they’re operating at fundamentally different levels. Unit testing won’t tell me:
a) If I’ve made a mistake in my logic
b) If I understand the problem space correctly
c) If my implementation is correct (in the “are these answers right?” sense)
d) If I understand the problems space <b>thoroughly</b> (obscure, hard-to-find & subtle edge cases are very common)
e) If my unit tests are reliable & complete – have they caught everything?
Unfortunately, thinking about this more, I’m not convinced that even unit testing PLUS my test rigs (yes, rigs. I lied before. I actually have two, no three, that grill the system from subtly different angles) are going to catch everything.
Of course, it’s a game of diminishing returns. How much time do I spend testing vs actually delivering resuilts?
Shifting to a higher level language helps – fewer lines of code = fewer bugs. It’s still a stop gap though. Programs are only getting larger & more complex.
Better architecture always helps of course – lower coupling = fewer cascading problems across sub-domains, but when we’re juggling tens, hundreds, or thousands of subsystems in a larger overall system?
I’m not convinced there’s an easy answer. And as software gets more complex, I only see the overall problem spiralling at some high power of that complexity. No matter how clever our test rigs, how well covered in tests our code is.. How do we move forward efficiently without getting bogged down in “Can we trust the results?”?
Right now, I just don’t know.
related
30.Jun.2008In what sequence are intra-bar orders hit? It’s not as straight forward as you’d think.
[Originally published Sep 2007]
Here’s a problem I spent a while thinking about and solving. It’s quite a core one, and a bit tricky on the edge cases.
Some background: I’m building a system trading backtesting engine. Well actually, I’ve finished building it. Now I’m just making it do fun things.
Anyway, so, we have a program (a “system”) that decides when to Buy & Sell (ie, places “orders” or “signals”, usually at a specific price) in the market. We then run that against a bunch of market data, and see how well it does. From this we either tweak the system, or trade it. Rinse, Repeat, this is more or less what I do all day. Well, I’m more on the testing side than the development side, but anyway, given the way things are going, that’s largely a moot point.
Here is the basic bar – in our case, daily. These are probably familiar to you, but can be a bit weird to start with. The way you interpret these is as follows. The little tick on the left is the Open Price. The tick on the right is the Close price. The line that goes up stops at the High price for the day, and the line that goes down stops at the Low price for the day. All the action happens between those points. However, this bar by itself doesn’t tell us anything about WHAT happened during that day. That’s where things get tricky.

So, the key question is – if we have multiple orders on that bar, how do we know which are hit, and in which order? This is important if we are to reliably determine how a system actually trades in the market place.
Of course, usually we only have one order per bar, so there is simply a question of “Was the order price within the range of the bar (>= L and <= H)?” If it’s within the range, then the order is hit, if not, not. Very simple1.
However, as we move to faster and faster systems – with greater likelihood of multiple orders (e.g. an entry and multiple exits) within the range of a single bar, things get more complicated. In order to decipher this accurately, the key question becomes:
What order did the Open, High, Low & Close occur in?
We don’t actually have any intra bar data, only the O, H, L & C prices. Nothing about which are hit first (although of course O is first, C last).
Depending on what we decide, we could end up flat when we should be in a position (or vice versa), or hitting a loss before a profit, thereby significantly affecting system profitability. The cumulative effect of these seemingly insignificant differences can easily result in very nasty “real time” surprises when we’re actually trading a system that may otherwise have tested positively.
The higher frequency the system (i.e., the more often it trades), the greater the likelihood of multiple signals on an individual bar. Cumulatively we could end significantly different from how the system will actually behave when traded.
Obviously the simplest solution is to get finer grained data – if we’re currently using daily, then use half hourly, etc. However:
a) no matter how fine grained, there will always be some signals on the same bar, &
b) what do we do when we don’t have, or choose not to use, finer grained data (eg for performance or cost reasons)?
—
My previous testing platform has a very simple policy. The shortest distance gets covered first, regardless of overall market direction. However this simple strategy is flawed.
For example, if the OHLC are O=660.15, H=662.25, L=658.15, C=658.50 (as on the S&P500, 19/Sep/1984), it trades thus:
660.15 (O) -> 658.15 (L) -> 662.25 (H) -> 658.50 (C)
because the distance from O->L is only 2, but the distance from O->H is 2.1.
However, this has a total market distance travelled of abs(658.15 – 660.15) + abs(662.25 – 658.15) + abs(658.50 – 662.25) = 2 + 4.1 + 3.75 = 9.85.
However, if you look at this bar, it’s a downward bar (i.e. C < O). In an overall downward trend it’s much more likely that the market would have hit the High first, then reversed, come down, hit the Low, then closed slightly higher, but still lower than Open, i.e.:
660.15 (O) -> 662.25 (H) -> 658.15 (L) -> 658.50 (C).
(i.e., a total market distance travelled of 2.1 + 4.1 + 0.35 = 6.55)
—
In order to unravel this, we need to figure out, for each possible type of bar, what order the OHLC would have been hit in. We can then “traverse” each leg of the bar in turn – in the above example, we travel from Open up to High, hitting any prices in that range, ranked from lowest to highest. We then travel from High down to Low, hitting any prices in that range, from highest to lowest. Finally we travel from Low up to Close, hitting prices from lowest to highest. Of course, any order hit can also trigger later orders which must also be accounted for and kept track of.
![]() Straight up. i.e. O=L, C=H
Straight up. i.e. O=L, C=H ![]() Straight down. i.e. O=H, L=C
Straight down. i.e. O=H, L=C
This is the simplest situation. The bar has only one leg, and simply traverses directly from O->C, regardless of overall market direction.
![]() Lower, but upwards. i.e. O <> L, C=H
Lower, but upwards. i.e. O <> L, C=H ![]() Lower, but downwards. i.e. O <> L, C=H
Lower, but downwards. i.e. O <> L, C=H
Slightly more complicated, this bar has two legs. The market first traverses from O->L, then from L->C. Whether the Open is the High, or the Close is the High is irrelevant. ![]() Higher, but upwards. i.e. C<>H, L=O
Higher, but upwards. i.e. C<>H, L=O ![]() Higher, but downwards. i.e. O<>H, L=C
Higher, but downwards. i.e. O<>H, L=C
As above, the bar has two legs. First from O->H, then from H->C. Overall trend is irrelevant.
![]() Upward only, but no overall movement. i.e. O=L=C, H diff
Upward only, but no overall movement. i.e. O=L=C, H diff ![]() Downward only, but no overall movement. i.e. O=H=C, L diff
Downward only, but no overall movement. i.e. O=H=C, L diff
These bars are relatively simple. Only two legs. On the left, O->H, H->C. On the right, O->L, L->C.
![]() All different, upwards. i.e. O<>H<>L<>C, C > O
All different, upwards. i.e. O<>H<>L<>C, C > O ![]() All different, downwards. i.e. O<>H<>L<>C, C < O
All different, downwards. i.e. O<>H<>L<>C, C < O
This is the controversial bar. In a long, upward bar (as on the left), it is rather unlikely (although not impossible, of course, just unlikely2) that the market would go from O->H, then all the way down to L, then back to C. So, the 3 legs we decide are O->L, then L->H, then H->C. On a downward bar (as on the right), we reverse the order, O->H, H->L, L->C.
![]() Completely flat. i.e. O=H=L=C
Completely flat. i.e. O=H=L=C
This is a rather silly bar. No legs to speak of, we just have to check if any orders hit the exact price (O=H=L=C). It’s debatable if anything would have traded, since markets this flat typically mean zero liquidity – i.e., no trades at that price.
![]() Up & downward, but no overall movement
Up & downward, but no overall movement
This is the most complicated case. How do we decide which order the prices were hit in?
Above we’ve been using the overall trend of the bar to decide. However, there is no trend here.
The simplest solution is to look at the previous bar (since we always have that data). If the trend from the previous bar is down, then we are likely at a trend reversal point. I.e., the previous bar the market was pushing downwards, like this:

The market continued downwards to the Low, then reversed, hit the High, then finally settles back at the Close. In other words, there wasn’t enough selling pressure in the market to push to a new low. Note that this is the exact opposite of our usual trend-based decision. Normally if the trend is down, we estimate that the High was hit first. Here we hit the Low first.
Of course, if the previous bar was an upward trending bar (C > 0) then we estimate that the High was hit first, then the Low, then Close (ie, O->H->L->C) – in other words, there wasn’t enough buying pressure to push to a Close above the Open.
Very occasionally you do get situations where you have several of these types of bars in a row – in which case we look back two bars, etc. Of course, accuracy drops, but fortunately this is rare enough not to worry about too much.
—
Hopefully, by combining all of these decisions, you end up with a much truer picture of what any system is doing, within any given bar. With all backtesting, it’s always a tradeoff of likely accuracy versus effort. How can you be sure you’re not over-optimizing? How can you be sure your system will trade exactly as it has tested? Is it worth the additional effort? Etc. This kind of analysis is just a small step closer to reality, in terms of simulated versus actual performance.
[ed: It turns out the above methodology is about 90% correct, in terms of OHLC order, vs ~80% for the “shortest distance first” strategy. It’s still not perfect, but it is a significant improvement & worth the extra clock cycles]
Footnotes
[1] Of course, there is also the question of whether our orders would be filled at EXACTLY the High or Low of the bar. i.e., should we use >=L & <=H or >L & <H?
[2] The entire strategy will never be 100% correct, of course, because any market will sometimes behave in unexpected ways. What we should attempt to do is get our estimates as close as reasonably possible to reality. More accurate = better informed decisions = greater likelihood of successfully trading systems.