The Next Generation of Neural Networks
Given that I spent five+ years of my life in the early 90’s doing nothing but eat, drink & dream neural networks, this Google talk by Geoffrey Hinton (one of the giants of nnets) was one of the most stimulating, exciting & thought provoking things I’ve ever seen. Plus he seems like a hell of a nice guy – has a great sense of humour.
It’s an hour long, but well worth allocating the time to watch. [No embed available, unfortunately]
If you’re in a rush, here’s the key bit: 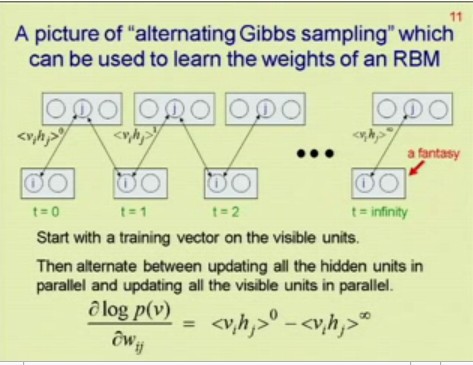
You’re very welcome. No need to thank me :)
It is, however, singularly awesome – took him 17 years to figure out, so appreciate it, damn it!
related
Unit Testing – Necessary, but Not Enough
I realised recently that I’d hit a point of diminishing returns. My overall code base was now so complex that any change I introduced in certain areas was taking exponentially longer to debug & ensure accuracy.
Of course, I had a test rig – otherwise how would I know what I was doing was correct in the first place?
The central core of all my systems is a rebuild of a now antiquated black box trading platform. I don’t have the source, but I need to duplicate the behaviour.
The test rig is pretty sophisticated – it didn’t start that way, and it shouldn’t really have needed to be, buuuuut
The old system:
1. Calculates using single precision floating point math.
If I need to explain why this is painful, check this out – if even the guys running Excel get occasionally tripped up by floating point math, what hope is there for the rest of us? Single point means there’s only half as many bits (32) to do maths in vs the default double (64 bits). Rough shorthand, single precision gives you get 6 decimal places. A number like ‘12000.25’, you’ll lose the ‘5’. If it’s negative, you’ll lose the ‘.25’. This means lots of rounding errors, and the more calculations you do, the more errors. The systems I’m working with do a LOT of calculations.
2. Rounds incoming numbers non deterministically
Mostly you can guess correctly what it’s going to decide a market price becomes, but particularly with markets that move in 1/32’s or 1/64 (ie, not simple decimals), this rounding becomes arbitrary if not damn ornery (rounded? no. up? no. down? no. truncated? no. based on equivalent string length? maybe)
3. Makes ‘interesting’ assumptions
Things like the order that prices get hit, how numbers are calculated internally (eg X = function(A/B) often returns a different result from Y = A/B; X = function(Y), that slippage only occurs in some situations and not others, and so on. Some make sense, in a way, many we don’t want. So now we have two modes of operation “old, broken, compatible, testable” and “new, not-broken, different numbers, untestable”
4. Has ‘chains’ of internal dependencies.
So, unsurprisingly, any of the above errors will then cascade through the output, fundamentally changing large chunks of the results.
So, the test rig allows for all this. Understands where common rounding problems occur, and how they cascade. Sorts by seriousness of the discrepencies, and so forth. Oh, and it does this by automatically tracking 60 or 70 internal variables for each calculation set across 7000 days on 60 markets. Ie, filtering & matching its way through 20-30 million data points.
But this still isn’t enough.
And this is where I see the light, and realise that this unit testing stuff that people have been raving about might actually be useful. So far, it has been. It’s enabled me to auto-scan a ton of possible problems, keep things in alignment as the system adjusts to changing requirements – all the palava you’ve read about.
But I’ve been thinking. No amount of unit testing would catch the errors my test rig will. Not that the rig is that amazing – just that they’re operating at fundamentally different levels. Unit testing won’t tell me:
a) If I’ve made a mistake in my logic
b) If I understand the problem space correctly
c) If my implementation is correct (in the “are these answers right?” sense)
d) If I understand the problems space <b>thoroughly</b> (obscure, hard-to-find & subtle edge cases are very common)
e) If my unit tests are reliable & complete – have they caught everything?
Unfortunately, thinking about this more, I’m not convinced that even unit testing PLUS my test rigs (yes, rigs. I lied before. I actually have two, no three, that grill the system from subtly different angles) are going to catch everything.
Of course, it’s a game of diminishing returns. How much time do I spend testing vs actually delivering resuilts?
Shifting to a higher level language helps – fewer lines of code = fewer bugs. It’s still a stop gap though. Programs are only getting larger & more complex.
Better architecture always helps of course – lower coupling = fewer cascading problems across sub-domains, but when we’re juggling tens, hundreds, or thousands of subsystems in a larger overall system?
I’m not convinced there’s an easy answer. And as software gets more complex, I only see the overall problem spiralling at some high power of that complexity. No matter how clever our test rigs, how well covered in tests our code is.. How do we move forward efficiently without getting bogged down in “Can we trust the results?”?
Right now, I just don’t know.