Si Dawson . Com
Cuil Really Isn’t (Yet)
There’s been a lot of grumping about Cuil lately, so I thought I’d add to it (hopefully in interesting new ways).
I’ll talk in context of a site that I have *cough* some familiarity with: galadarling.com (hint: I built & managed it for the last two years). This site gets over 100k uniques a week, has a google pagerank of 6, and a technorati rank in the mid 5000’s. I.e., it’s not Yahoo, but it is a significant, popular smaller site.
The obvious test – surely searching for gala darling would return the site? It’s not complicated. Her name is the url. But no:
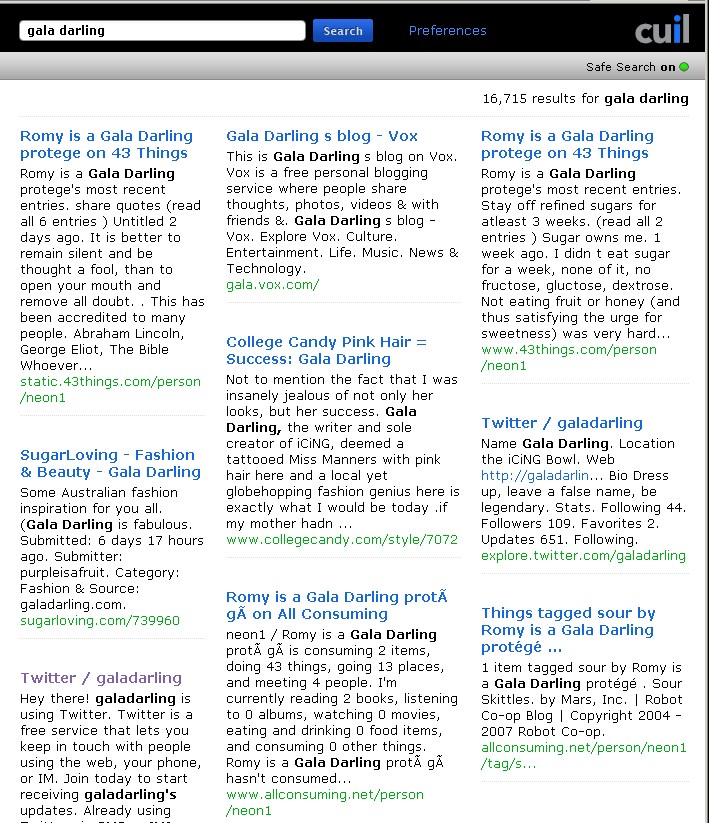 (click for a clearer view)
(click for a clearer view)Maybe it’s the safe search? No, flick that off, and exactly the same results:
 (click for a clearer view)
(click for a clearer view)Putting in “gala darling” in quotes (just like that) results in the exact same result set. Huh?
Even scarier, putting in galadarling (all one word) doesn’t even return the site. How is this possible?
Even worse than that – gala.vox.com is the second returned result. This is a single page that was setup once and then ignored. It’s not just not finding the correct result, it’s actively returning junk.
None of these sets include Gala’s livejournal, which is updated every couple of weeks, let alone the actual site that has her name on it.
With the exception of her twitter account, all the results on the front page are other sites, talking about her… and this is useful.. how?
I looked at the first 20 pages of results – couldn’t find either her livejournal or main site. vox.com somehow managed to get several hundred mentions. A single collegecandy page appeared at least 5 times.
Ok, it’s common knowledge that the Cuil results are crap. How about some other things.
- When you first load the page, you have to actually click to get into the textbox to enter your search terms.
- For some reason I’m asked to accept cookies both from cuil.com (fair enough), and cuilimg.com (what? why?)
- When paging through the results, there’s no way to go back to the start, as once you get past page 10, the earlier pages scroll off to the left, so you have to go backwards in chunks of 4 or 5.
- There’s no way to get more results on a screen. Even on my 1900 pixel wide screen & a tiny font, I still only get 10ish results per page. Google allows me 100 – why should I click-wait-click-wait just to use Cuil?
To their credit, Cuil’s bot is not hitting the site anywhere near as much as it used to, so that’s one good thing. Considering galadarling is updated typically once a day, plus maybe a hundred comments, the Cuil bot (twiceler) used to hit the site about a thousand times a day (resulting in it getting blocked by damn near everyone). For comparison, Google’s bots hit it 400 times a day (partly that will be because there is context-sensitive advertising on the site, so Google needs to scan for that). Now Twiceler is visiting about a hundred times a day – much more reasonable given the update frequency.
I’ve talked to the guys running Cuil (back when it still had two ‘l’s in its name). They’re obviously very smart cookies and they definitely care about what they do. If they can shake Google up – well, great – and I say that as a Google shareholder. They definitely have a lot of bugs to iron out though, and the reliability of those results needs to be right at the top of the list. Without trust, what do they have?