What To Do When The Pope Spams You
Aka: How to do POST requests using Curl
My parents, being Catholic, signed up for a newsletter from the Vatican (as one does).
After a year or so of receiving it, they eventually realised they weren’t really reading it, and wanted to unsubscribe.
No problem. At the bottom of each message is the legally required footer:

Cancellare – that sounds about right (why the footer is in Italian when the rest of the newsletter is in English I have no idea).
Clicking Cancel(lare) takes you to this page:

With the default language set to Italian, despite coming from our English newsletter (nice one).
You can change the language at the top from Italiano to Inglese (USA) – although again, why it’s necessary to specify the USA version of English (not just “Inglese”) on a subscription management page, I have no idea.
It then looks like this:
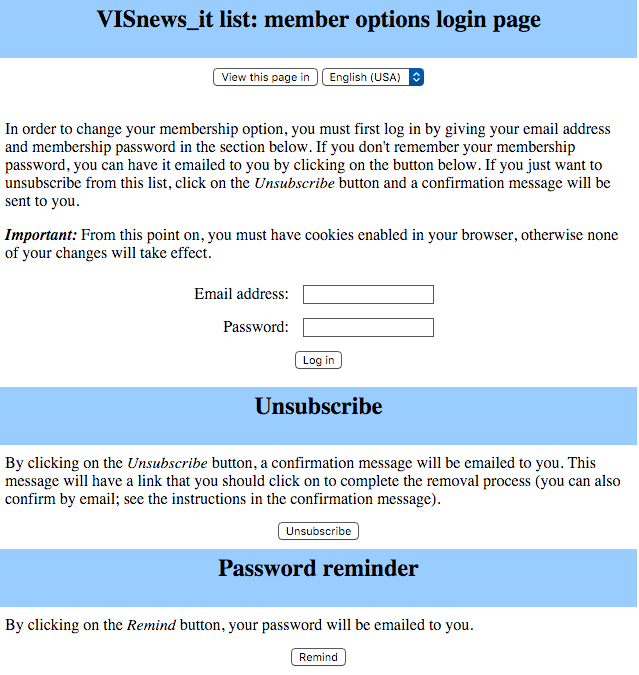
Ok, so far so good.
Now. Just enter your email address (easy) and password, and we can begin.
Oh. What’s the password?!? Well hell, do YOU remember the passwords to every obscure service you signed up to a year ago that you haven’t thought about since?
Minor speed bump.
What about if we try it without our password? After all, unsubscribing should be easy. I mean, The Vatican, of all places, wouldn’t consciously want to SPAM people, would they?
So, enter your email address, click “Unsubscribe” and voila. The page refreshes, and you get a helpful message:
![]()
Except nothing actually happens. The unsubscribe email never arrives.
Now, there’s another fairly major niggle here – why the hell is it a double opt-in to unsubscribe? That’s VERY spammy. Lists should be hard to get onto (ie, double opt-in) – so, say, someone else can’t accidentally put your email address on a list. They should be easy to get off of. The Vatican has this completely ass-backwards. It’s spammy.
Ok, anyway, maybe we can get our password, and then change our email address to something that doesn’t work (fuckoff@nospam.com is a personal favourite).
Now our email address is entered we can click the Password Reminder button “remind”.
Except the password reminder button doesn’t work either.
You can click it – as many times as you like – and nothing happens. Ever.
So. What next? Well. We could try emailing them directly (no response), or via their contact form (no response). Several times, in fact (no response).
One day, The Vatican in its infinite kindness will get around to fixing this page. In the meantime they’ll keep happily blasting out emails every day, no doubt delighted in how many (angry and frustrated) believers they’re reaching.
However, as soon as the page IS fixed, we’d like to be off the damn list please. And I mean, within the day.
Enter Curl, stage left.
Curl is a nifty little unix app mostly used for getting web pages. It’s very helpful for things like debugging sites, because you can use it to view the headers on a site, like this:
curl -I -L google.com
(-I == just show the headers not the page content, -L == follow redirects)
Which shows lots of groovy useful technical stuff. If you’re into that kind of thing (I occasionally am).
However, a lesser known use of curl is to make POST requests (like entering a form) not just GET (getting a web page). Unsurprisingly, being unix, there’s a billion other things you can do with Curl, but we’ll stick to POST for today.
To do this, we just have to have a nosey into the page content, find the forms we want to enter the data for, and which fieldnames we want to use.
So, if we look at our Cancellare page, the HTML looks like this:
<FORM action="../options/visnews_it" method="POST" > <INPUT name="email" type="TEXT" value="" size="20" > <INPUT name="password" type="PASSWORD" value="" size="20" > <INPUT name="login" type="SUBMIT" value="Log in" > <INPUT name="login-unsub" type="SUBMIT" value="Unsubscribe" > <INPUT name="login-remind" type="SUBMIT" value="Remind" > </FORM>
I’ve stripped out all the other HTML junk (tables, text etc) and just left the form and inputs.
So, you can see – there’s a place to enter email, password, and then three submit buttons. One to login, one to unsubscribe, one to send a password reminder.
Why would we want Curl here?
Well, we can make Curl do this form request for us. We don’t have to start up a browser and enter all our details manually. Every day. Forever. Until they fix their site.
The command line goes like this:
curl –data “name=value&name=value&name=value” FORM_ACTION_URL
The form action URL (if you follow their up-and-down–into-the-same-directory bit) is http://mlists.vatican.va/mailman/options/visnews_it
We also want to enter our email address, and then finally, click the unsub button.
Thus, the name/value bit ends up:
email=[our email address]&login-unsub=Unsubscribe
If we wanted to get curl to send us a password reminder, we’d just change it to
email=[our email address]&login-remind=Remind
The only gotchya is that you can’t send @ characters. You have to escape them. So, instead of “email=bob@smith.com”, you’d have to use “email=bob\%40smith.com”
Thus the entire line become
curl –data “email=bob\%40smith.com&login-unsub=Unsubscribe” http://mlists.vatican.va/mailman/options/visnews_it
Finally, chuck the whole thing into crontab to run every 6 hours:
3 */6 * * * curl –data “email=[our email addr]&login-unsub=Cancellami” http://mlists.vatican.va/mailman/options/visnews_it > /dev/null 2>&1
and voila. (The “> /dev/null 2>&1” is just dark magic to say “ignore all output, even errors”)
Oh, login-unsub is set to Cancellami just because that’s what the original Italian form had. I figured they’d be more likely to fix the Italian unsubscribe before they fixed the English one (if they’re set up independently).
Once the Vatican gets their site working again, we’ll get an email (well, four a day), then we can click unsubscribe and I’ll delete the one line cron job. Easy. Until then, we’ll just delete the spam, happy in the knowledge that our little curl robot is taking care of things for us in the background.
related
Some Swype Tips
I first saw Swype (the funky text entry system) on a friend’s Android phone several years ago. So, you can imagine how eagerly I awaited it on iOS, and my excitement when it finally arrived. I’d estimate it at roughly three times faster than the built in iOS keyboard (which itself is something of a technical marvel).
Needless to say, while Swype truly is great, it still has a few rough edges. However, with some judicious googling, moderate experimentation and a lot of hunting through forums, I’ve found a few hidden gems that makes using it a LOT less painful.
(because keys aren’t hit one after another, I’ll describe Swype motions with hyphens. Eg, Swyping cat would be c-a-t – ie, you start at c, then swipe your finger up to a, then across to t)
Handy Shortcuts
- comma-space gives you a comma followed by a space
- fullstop-space gives you a full stop followed by a space
- l-space gives you “
- x-space or z-space gives you !
- m-space gives you ?
- You can swipe directly from the 123 button to any of the keys on that second key layout (all the numbers and common non-alpha characters) without having to change from normal entry mode
Swype key(the ‘S’, bottom left)-gear icon takes you to options. From here you can see your personal dictionary, and delete items (by swiping left) if you want to get rid of them. You can also change the colour of the keyboard, etc.
The REAL best secret tip
Most useful though? If you click-and-hold on a word on the word bar (the list of words that appears just above the keyboard), you can delete words from the dictionary. This includes words in THEIR dictionary, not just your own. This is BRILLIANT.
The reason this is so helpful? Because so often we’ll end up accidentally dragging across words we didn’t intend. And there are some REALLY dopey words in there that are very close to common ones. Eg, Bachmann (as in Michelle Bachmann, American right wing banana) instead of Banana. Abutting is right next to Anything. Luge disrupts my attempts at Life. Etc. So, when you find a silly word appearing, pause, swipe the same word a few times until you see the stupid word in the wordbar, then press and hold and you’ll delete it. Voila, it’ll never pop up again.
Other stupid words are things like “m.p.h”, so anytime you swipe m-. instead of .-space (both VERY close to each other) you get “m.p.h” instead of “. ” *SIGH* I spent WEEKS manually backspacing “m.p.h” until I learned about the word delete trick. Since then, ahh, I’ve probably saved myself from having to delete it 15-20 times a day. Excellent.
I’ve also found that deleting names (proper nouns) I know I’m never going to need (I can always type them in manually if I ever do use them) – eg I would always get Erik, instead of With – made a huge difference in terms of how often incorrect words appeared.
By the time you’ve deleted 20-30 of your common mis-swypes (and they vary from person to person – all our hands are different sizes, etc), you’ll find that the keyboard works very noticeably better.
related
09.Feb.2012How to do a multi-table update with a limit in MySQL
According to the MySQL documentation, you can’t do a multi-table UPDATE with a LIMIT.
What’s a multi-table update with a limit? Well, something like this:
UPDATE
foo
, bar
SET
foo.baz=bar.baz
WHERE
foo.baz IS NULL
AND foo.id=bar.id
LIMIT
1000
;
(Which doesn’t work. Of course, you can do single table UPDATEs with a LIMIT just fine)
Why would you even want to do this?
Well, anytime you have monster sized tables, and you don’t want to lock everybody else while you either read (from bar) or write (to foo). If you can put a limit on the update, you can call it repeatedly, in small chunks, and not choke everything for all other users.
For example, if bar happens to have, say, ohhh, 30 million rows in it, foo happens to have ooh, 2 million rows and they’re both used by everything, all the time.
So, here’s a sneaky way to get around this limitation. I did promise one, right there in the title, after all.
UPDATE
foo
, (SELECT
bar.id
, bar.baz
FROM
foo
, bar
WHERE
foo.id=bar.id
AND foo.baz IS NULL
LIMIT
1000
) tmp
SET
foo.baz=tmp.baz
WHERE
foo.id=tmp.id
;
Some important notes:
- The update conditions (foo.baz IS NULL) go inside the subquery, along with the LIMIT.
- We have to match ids twice – once for the subquery, and once against the created temporary table. That’s why we make sure we SELECT both the id and baz from bar in the subquery.
- There’s no conditionals (other than id match) on the outside WHERE condition, since we’ve done them all in the subquery.
- MySQL also has a limitation of not allowing you to UPDATE while SELECTing from the same table in a subquery. Notice that this sneakily avoids it by only SELECTing from the other table.
So, how about that? You can now do limited multi-table updates.
Oh, except for one. Minor. Problem.
This doesn’t work with temp tables (eg if foo was created with a CREATE TEMPORARY TABLE statement).
Bugger.
However, here’s a sneaky way around that limitation too.
First of all, give your temp table another column, in the example below “ref_no INT”.
Make sure you have an index on the id, otherwise it’ll be dog slow.
Then do this:
# do this in chunks of 1k
SET @counter = 1;REPEAT
UPDATE
tmp_foo
SET
ref_no=@counter
WHERE
ref_no=0
AND baz IS NULL
LIMIT
1000
;
COMMIT;UPDATE
tmp_foo
, bar
SET
tmp_foo.baz=bar.baz
WHERE
tmp_foo.ref_no=@counter
AND tmp_foo.id=bar.id
;
COMMIT;SET @counter = @counter + 1;
UNTIL (SELECT COUNT(id) FROM tmp_foo WHERE ref_no=0 AND baz IS NULL) = 0
END REPEAT;
Some important notes:
- We’re basically flagging a thousand rows at a time, then matching only against those rows – pretty simple concept really.
- The commits are in there because MySQL can be a bit weird about not propagating changes to the database if you don’t commit inside your stored proc. This ensures that updates are passed out, which also means I can run multiple copies of this stored proc concurrently with moderate safety (if I replace @counter with a suitably large RAND() value) – well, as much as you can normally expect with MySQL anyway.
- If you want to reuse the temp table (say, to update something else from – a reverse update to that shown above) you’ll need to reset all the ref_no’s to 0.
- Whatever conditions are in the initial WHERE need to be mirrored in the final SELECT COUNT.
- Obviously just drop the table when you’re finished.
As a bonus, I’ve found this is actually quicker than doing one single large scale update. Why? Less memory is used.
So look at that. TWO ways to get multi-table updates with a limit. Nifty.
related
09.Feb.2012How to automatically position PuTTY terminal
PuTTY is arguably the best Windows terminal app. I’ve used it for years.
One thing that has always felt missing is the ability to automatically position it on the screen on startup. For example, I always have a couple of windows where I watch certain processes. They’re always in the same position on my screen, and always running the same scripts inside them. How do I do that?
So, you can imagine my glee when I found a patch out there that will do exactly that. Props go to Brad Goodman who wrote it. Follow that link to get both an exe (his patch applied to a 2005 build) and the source so you can patch it yourself. I’ve also put a copy of the exe here, in case his site disappears.
How to use it? Very simple.
- Save your session settings from inside PuTTY, as normal
- Start up putty-bkg.exe (instead of the usual putty.exe)
- Now when you load your sessions you’ll also see the new “Position & Icon” options, under “Window”:

Enter the desired top, left (& icon, if you feel inspired)
- Alter them to your heart’s content (don’t forget to also adjust the rows & columns under “Window” to get it the right size too), save your session and voila.
Even more useful is if you combine this with setting a remote command to be run at initial connection.
- Click on “SSH” under “Connection” (you can’t do this if the session is already active)
- Enter the command or script you want run in the “Remote Command” textbox:
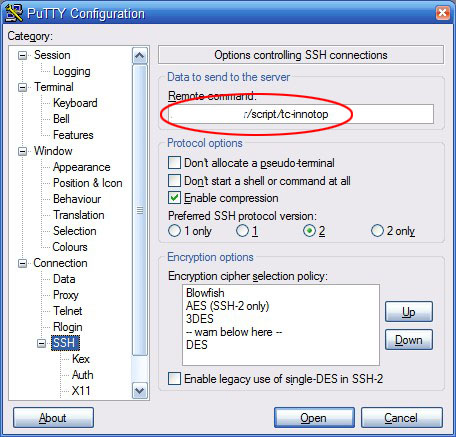
Enter the startup command
- Click the “Save” button (under “Session”) as usual.
Now, to run all of the above, just setup a shortcut to:
“C:\Program Files\putty\putty-bkg.exe” -load [session name]
(where [session name] is whatever you saved your session as). Obviously adjust the path to wherever you put putty.bkg.exe.
Next time you click the shortcut, not only will PuTTY be positioned correctly on the screen, but it’ll also automatically be running whatever script you desire. Just like magic! (but with less jiggery pokery)
related
30.Mar.2009The Importance Of Pipes
There’s a very subtle, often overlooked thing in Unix, the pipeline, or | character (often just called a pipe).
This is perhaps the most important thing in the entire operating system, with the possible exception of the “everything is a file” concept.
In case you’re unfamiliar (or didn’t feel like reading the wiki page above), here’s the basic concept:
A pipe allows you to link the output of one program to the input of another.
eg foo | bar – this takes the output from foo, and feeds whatever-it-is into bar – rather than, say, having to point bar at a specific file to make it do anything useful.
Why are pipes so awesome?
Well, the following reasons:
- Each program only has to do one thing, & do it well
- As such, development of those programs can be split up – even to the point where a thousand people can independently write a thousand programs, & they’ll all still be useful
- Each of those programs is very simple, thus faster to develop, easier to debug, etc
- Extremely complex behaviour can be created by linking different programs together in different ways
- None of that higher level behaviour has to be pre-thought or designed for
So, Unix has ended up with a ton of small but powerful programs. For example:
- ls – lists a directory
- cat – displays stuff
- sort – sorts stuff
- grep – finds things in stuff
- tr – translates stuff (eg, upper to lower case)
- wc – counts words or lines
- less – pauses stuff, allowing forwards & backwards scrolling
I’ve been deliberately vague with the descriptions. Why? Because ‘stuff’ can mean a file – if we specify it, or, it can mean whatever we pass in by putting a pipe in front of it.
So here’s an example. The file we’ll use is /usr/share/dict/words – ie, the dictionary.
cat /usr/share/dict/words
displays the dictionary
cat /usr/share/dict/words | grep eft
displays dict, but only shows words with ‘eft’ in them
cat /usr/share/dict/words | grep eft | sort
displays ‘eft’ words, sorted
cat /usr/share/dict/words | grep eft | sort | less
displays sorted ‘eft’ words, but paused so we can see what the hell we’ve got before it scrolls madly off the screen
cat /usr/share/dict/words | grep eft | grep -ve ‘^[A-Z]’ | sort | less
displays paused sorted ‘eft’ words, but removes any that start with capital letters (ie, all the Proper Nouns)
cat /usr/share/dict/words | grep eft | grep -ve ‘^[A-Z]’ | wc -l
gives us the count of how many non proper-noun ‘eft’ words there are in the dictionary (in the huge british english dictionary? 149, since I know you’re curious)
So there’s an additional benefit which is probably obvious. Debugging a complex set of interactions with pipes is incredibly straightforward. You can simply build up what you think you need, experimenting a little at each stage, & viewing the output. When it looks like what you want, you just remove the output-to-screen, and voila!
For the end-users, this means that the operating cost of using the system in a complex manner is drastically reduced.
What would happen without pipes? You’d end up with monolithic programs for every imaginable combination of user need. Ie, an unmitigated disaster. You can see elements of this in, umm, ‘certain other’ operating systems. *cough*
Most importantly of all, there is a meta benefit. A combination of all of the above benefits.
Pipes enable incredibly complex higher level behaviours to emerge without being designed in. It’s a spontaneous emergent behaviour of the system. There’s no onus on the system development programmers to be demi-gods, all they need to do is tackle one simple problem at a time – display a file, sort a file, and so on. The system as a whole benefits exponentially from every small piece of added functionality, as pipes then enable them to be used in every possible permutation.
It’s as if an anthill full of differently talented ants was suddenly building space ships.
Perhaps a better bits-vs-atoms metaphor is of money. Specifically the exchange of goods (atoms) for money, allows the conversion of those atoms into other atoms, via money. In the same way, pipes allows different programs to seamlessly interact via streamed data, in infinitely variable ways.
You don’t need to know how to make a car, since you can do what you’re good at, get paid, & exchange that money for a car. Or a boat. Or a computer. Society as a whole is vastly better off as each person can specialize & everybody benefits. Think how basic our world would be if we only had things that everybody knew how to build or do. Same thing with computers & pipes.
What seems like an almost ridiculously simple concept, pipes, has allowed an unimaginably sophisticated system to emerge from simple, relatively easily built pieces.
It’s not quite the holy grail of systems design, but it’s bloody close.
related
16.Dec.2008A Nifty Non-Replacing Selection Algorithm
Algorithms are awesome fun, so I was super pleased when my little bro asked me to help him with a toy problem he had.
The description is this: It’s a secret santa chooser. A group of people, where each person has to be matched up with one other person, but not themselves.
He’s setup an array that has an id for each person.
His initial shot was something like this (pseudo, obviously):
foreach $array as $key => $subarr {
do {
// $count is set to count($array)
$var = rand(0, $count)
} while $var != $key and $var isn't already assigned
$array[$key][$assign] = $var
}
Initially he was mostly concerned that rand would get called a lot of times (it’s inefficient in the language he’s using).
However, there’s a ton of neat (non-obvious) problems with this algorithm:
- By the time we’re trying to match the last person, we’ll be calling rand (on average) N-1 times
- As a result, it’s inefficient as hell ( O(3N+1)/2)? )
- There is a small chance that on the last call we’ll actually lock – since we won’t have a non-dupe to match with
- Not obvious above, but he also considered recreating the array on every iteration of the loop *wince*
Add to this some interesting aspects of the language – immutable arrays (ie, there’s no inbuilt linked lists, so you can’t del from the middle of an array/list) & it becomes an interesting problem.
The key trick was to have two arrays:
One, 2-dimensional array (first dim holding keys, second the matches)
and one 1-dimensional array (which will only hold keys, in order).
Let’s call the first one “$list” and the second “$valid”.
The trick is this – $valid holds a list of all remaining valid keys, in the first N positions of the array, where initially N = $valid length. Both $list & $valid are initially loaded with all keys, in order.
So, to pick a valid key, we just select $valid[rand(N)] and make sure it’s not equal to the key we’re assigning to.
Then, we do two things:
- Swap the item at position rand(N) (which we just selected) with the Nth item in the $valid array, &
- Decrement N ($key_to_process).
This has the neat effect of ensuring that the item we just selected is always at position N+1. So, next time we rand(N), since N is now one smaller, we can be sure it’s impossible to re-select the just selected item.
Put another way, by the time we finish, $valid will still hold all the keys, just in reverse order that we selected them.
It also means we don’t have to do any array creation. There’s still a 1/N chance that we’ll self-select of course, but there’s no simple way of avoiding that.
Note that below we don’t do the swap (since really, why bother with two extra lines of code?) we simply ensure that position rand(N) (ie, $key_no) now holds the key we didn’t select – ie, the one that is just off the top of the selectable area.
Oh, and in this rand implementation rand(0, N) includes both 0 AND N (most only go 0->N-1 inclusive).
$valid = array_keys($list);
$key_to_process = count($valid) - 1;
do {
$key_no = rand(0, $key_to_process);
if ($key_to_process != $valid[$key_no]) {
$list[$key_to_process][2] = $valid[$key_no];
$valid[$key_no] = $valid[$key_to_process];
$key_to_process--;
}
# deal with the horrid edge case where the last
# $list key is equal to the last available
# $valid key
if ($key_to_process == 0 and $valid[0] == 0) {
$key_no = rand(1, count($list) - 1);
$list[0][2] = $key_no;
$list[$key_no][2] = 0;
$key_to_process--;
}
} while ($key_to_process >= 0);
Without the edge-case code, this results in a super fast, nice slick little 10 or so line algorithm (depending on how/if you count {}’s :)
Elegant, I dig it.
related
16.Sep.2008The Trouble With Ratios
Ratios are used all over the place. No huge surprise there – they are, after all, just one number divided by another.
The well known problem case is when the denominator (the bottom bit) is zero, or very near zero. However, there are other subtler issues to consider.
Here’s a chart that has a ratio as the X axis:
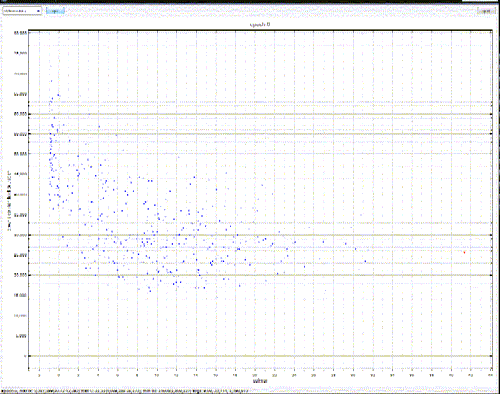
Don’t sweat the details, they’re not terribly important – just the rough distribution.
The X axis in this case is what’s called a Calmar – ie, the total dollar return of a system divided by it’s maximum drawdown. Or, in English – how much you make proportional to how big your pockets need to be. This gives a non-dollar based (ie, “pure”) number that can then be compared across markets, systems, products, whatever.
This graph is actually a bit trickier than that, since there’s actually 3 dimensions of data there – it’s just the third dimension isn’t plotted – but we’ll get back to that.
Where this gets ugly is when, in the case of the Calmar above, the drawdown drops to, or near to, zero. For example, if you have a system that only trades once – and it’s a winning trade – the calmar will be very, very large. Even if you chuck out systems that are obviously a bit nutty like that, you can still end up with situations where the ratio has just blown out of all proportion.
Which results in this:
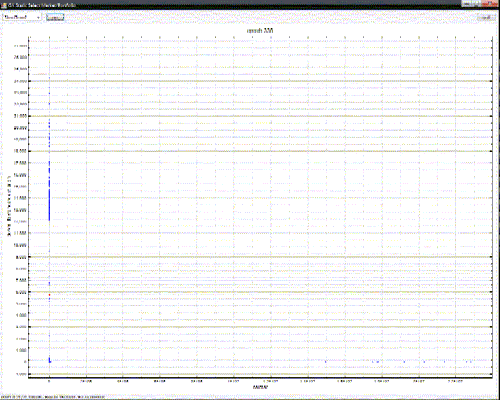
See how everything is in a vertical line on the left?
Well, it’s not. Those points are actually quite well spread out – it’s just that instead of the X axis going from 0->50 as in the first case, it now goes from 0->22 million – of which only a small number are greater than a hundred (you can see them spread out on the right, very close to the Y axis)
In this example, we can see the problem, so we’re aware of it. However, what if the ratio had been the unplotted third dimension? We might never have known.
Now, the way that I’m using these ratios internally, I’m protected from these sorts of blowouts – I simply compare sets of ratios. If one is bigger, it doesn’t matter if it’s bigger by 2 or by 2 billion.
However, there are many situations where you might want proportional representation. If one value is twice as big, say, it should occur twice as often. In this case, ratios that explode out by orders of magnitudes quickly swamp results, and drive the whole thing into the ground.
You swiftly end up with a monoculture. One result eats all the others, and instead of a room full of happy spiders doing their thing, you end up with one fat angry spider in the middle of the room. Umm, so to speak.
Ratios can be dangerous, kids. Watch out!
related
02.Jul.2008Unit Testing – Necessary, but Not Enough
I realised recently that I’d hit a point of diminishing returns. My overall code base was now so complex that any change I introduced in certain areas was taking exponentially longer to debug & ensure accuracy.
Of course, I had a test rig – otherwise how would I know what I was doing was correct in the first place?
The central core of all my systems is a rebuild of a now antiquated black box trading platform. I don’t have the source, but I need to duplicate the behaviour.
The test rig is pretty sophisticated – it didn’t start that way, and it shouldn’t really have needed to be, buuuuut
The old system:
1. Calculates using single precision floating point math.
If I need to explain why this is painful, check this out – if even the guys running Excel get occasionally tripped up by floating point math, what hope is there for the rest of us? Single point means there’s only half as many bits (32) to do maths in vs the default double (64 bits). Rough shorthand, single precision gives you get 6 decimal places. A number like ‘12000.25’, you’ll lose the ‘5’. If it’s negative, you’ll lose the ‘.25’. This means lots of rounding errors, and the more calculations you do, the more errors. The systems I’m working with do a LOT of calculations.
2. Rounds incoming numbers non deterministically
Mostly you can guess correctly what it’s going to decide a market price becomes, but particularly with markets that move in 1/32’s or 1/64 (ie, not simple decimals), this rounding becomes arbitrary if not damn ornery (rounded? no. up? no. down? no. truncated? no. based on equivalent string length? maybe)
3. Makes ‘interesting’ assumptions
Things like the order that prices get hit, how numbers are calculated internally (eg X = function(A/B) often returns a different result from Y = A/B; X = function(Y), that slippage only occurs in some situations and not others, and so on. Some make sense, in a way, many we don’t want. So now we have two modes of operation “old, broken, compatible, testable” and “new, not-broken, different numbers, untestable”
4. Has ‘chains’ of internal dependencies.
So, unsurprisingly, any of the above errors will then cascade through the output, fundamentally changing large chunks of the results.
So, the test rig allows for all this. Understands where common rounding problems occur, and how they cascade. Sorts by seriousness of the discrepencies, and so forth. Oh, and it does this by automatically tracking 60 or 70 internal variables for each calculation set across 7000 days on 60 markets. Ie, filtering & matching its way through 20-30 million data points.
But this still isn’t enough.
And this is where I see the light, and realise that this unit testing stuff that people have been raving about might actually be useful. So far, it has been. It’s enabled me to auto-scan a ton of possible problems, keep things in alignment as the system adjusts to changing requirements – all the palava you’ve read about.
But I’ve been thinking. No amount of unit testing would catch the errors my test rig will. Not that the rig is that amazing – just that they’re operating at fundamentally different levels. Unit testing won’t tell me:
a) If I’ve made a mistake in my logic
b) If I understand the problem space correctly
c) If my implementation is correct (in the “are these answers right?” sense)
d) If I understand the problems space <b>thoroughly</b> (obscure, hard-to-find & subtle edge cases are very common)
e) If my unit tests are reliable & complete – have they caught everything?
Unfortunately, thinking about this more, I’m not convinced that even unit testing PLUS my test rigs (yes, rigs. I lied before. I actually have two, no three, that grill the system from subtly different angles) are going to catch everything.
Of course, it’s a game of diminishing returns. How much time do I spend testing vs actually delivering resuilts?
Shifting to a higher level language helps – fewer lines of code = fewer bugs. It’s still a stop gap though. Programs are only getting larger & more complex.
Better architecture always helps of course – lower coupling = fewer cascading problems across sub-domains, but when we’re juggling tens, hundreds, or thousands of subsystems in a larger overall system?
I’m not convinced there’s an easy answer. And as software gets more complex, I only see the overall problem spiralling at some high power of that complexity. No matter how clever our test rigs, how well covered in tests our code is.. How do we move forward efficiently without getting bogged down in “Can we trust the results?”?
Right now, I just don’t know.