Building Stencyl Haxe files inside Sublime Text
Building Haxe files inside Sublime Text is pretty much a solved problem, thanks to the Haxe-Sublime-Bundle.
However, using Sublime to externally edit Stencyl Haxe files is a bit trickier, since Stencyl has a ton of dependencies.
Of course, this makes developing much easier and faster, but the build is a bit more complicated than the standard build bundle can handle.
The standard edit/build cycle is:
- In Stencyl, click to edit the file externally
- Edit in Sublime Text (the built in Stencyl editor is pretty crap)
- Save
- Swap back to Stencyl
- Save again (because Stencyl is a bit daft)
- Click the Check Syntax button (there’s no keyboard shortcut)
This takes maybe ten seconds, which includes quite a bit of messing around, plus using the mouse (always slower).
Here’s a much faster way (Mac only. Sorry if you’re on Windows, you’ll need to convert the bash script to DOS. If you’re on Linux, you may need to tweak the gamename= line):
Create a bash script for the actual build:
#!/bin/bash
# parameters – filename to build (including path)
gamespath=/c/g/dev/stencylworks/games-generated
if [[ $1 == */* ]]; then
sourcefile=$1
else
sourcefile=$(pwd)/$1
fi# find current game
cd $gamespath
gamename=$(find ./ -iname *.hx -type f | sed -e ‘s/ /\\ /g’ | xargs ls -tr | tail -1 | cut -d “/” -f3)cp $sourcefile “./$gamename/Source/scripts/”
cd $gamespath/$gamename
/Applications/Stencyl/plaf/haxe/haxe -cp Source/ -cp Export/flash/haxe/ Export/flash/haxe/debug.hxml
You’ll need to change the gamespath (at the top) to wherever you’ve decided to save your Stencyl games. Specifically, the games-generated directory.
The matching against $1 just means if you pass in a full path (as Sublime Text does) then it uses that. If you’re in a directory and just pass the filename (as you would if you ran the script from the commandline) it’ll auto-add the current directory.
The only vaguely tricky bit is the line that finds the game name for the most recently edited file (ie, the one you’re working on). You can pretty much ignore that line of gibberish, but hey, if you REALLY want to know…
First it finds all the .hx files in the games-generated subdirectories. Sed sorts out any spaces in the paths (so the remaining commands don’t puke), passes the whole lot through to ls to sort by time (so the newest one is last). Tail gets the last one. And cut gives us the root directory – ie, the game name.
Complicated, but it works.
The last line, starting “/Applications/Stencyl” is all one line (in case it line-wraps on your screen)
(don’t forget to chmod +x the file so it’ll execute)
So, that’s bash.
On the Sublime Text side, you need to do the following:
1. Tools | Build System | New Build System
2. Enter the following:
{
“cmd”:[“/usr/local/bin/build_stencyl_haxe”, “$file”],
“selector”:”source.hx”,
“env”:{“HAXEPATH”:”/Applications/Stencyl/plaf/haxe/”, “HAXE_STD_PATH”:”/Applications/Stencyl/plaf/haxe/std”}
}
3. Save the file as haxe.sublime-build in the directory it defaults to
Now, some important notes here.
- You’ll need to replace the /usr/local/bin/build_stencyl_haxe with wherever you’ve saved the bash script above
- The selector line just means that the auto build chooser will identify any *.hx files as haxe files and use this build command set. That’s the theory. However, there’s an hxml build built in, which doesn’t take into account the Stencyl specifics. So, auto-build won’t work anyway. This isn’t a big deal, you’ll just need to select Tools | Build System | Haxe to manually select the build type. Hardly the end of the world. If anyone knows how to stop the default hxml type from taking precedence, I’d be curious to know.
- The env line I’ve had to put in because I have a couple of different versions of Haxe on my system. This ensures that the build process runs the Stencyl version of the libraries, so nothing gets confused. You may not need that. If you delete that line, be sure to remember to delete the trailing comma from the end of the selector line, otherwise Sublime Text will complain
When you’re done, just save it in the current directory (it’ll be something like ~/Library/Application Support/Sublime Text 2/Packages/User) with the name Haxe.sublime-build. Whatever you put before the ‘.’ is whatever will appear in your Build Tools menu.
So, that looks like a lot, and it did take me a good solid day to nut it all out and get it working well. There’s really not much though – c&p the bash file somewhere, change the path, save & chmod it, then c&p the build file into a new build tool option, point it at your bash script, save it and you’re pretty much done.
Here’s the good news:
- You don’t even have to save the file in Sublime Text in order to run the build – it’ll auto save
- If you’ve got the Built type selected in Sublime Text, a simple Command-B (on Mac) will build it
- It typically takes me 0.3s to build the file (if it finds an error, a bit over a second for a full game build) – whereas all that fiddling around back and forth to Stencyl took around 10.
For something you’re likely be doing hundreds of times a day as part of your core dev cycle, that’s a huge gain.
related
How to do a multi-table update with a limit in MySQL
According to the MySQL documentation, you can’t do a multi-table UPDATE with a LIMIT.
What’s a multi-table update with a limit? Well, something like this:
UPDATE
foo
, bar
SET
foo.baz=bar.baz
WHERE
foo.baz IS NULL
AND foo.id=bar.id
LIMIT
1000
;
(Which doesn’t work. Of course, you can do single table UPDATEs with a LIMIT just fine)
Why would you even want to do this?
Well, anytime you have monster sized tables, and you don’t want to lock everybody else while you either read (from bar) or write (to foo). If you can put a limit on the update, you can call it repeatedly, in small chunks, and not choke everything for all other users.
For example, if bar happens to have, say, ohhh, 30 million rows in it, foo happens to have ooh, 2 million rows and they’re both used by everything, all the time.
So, here’s a sneaky way to get around this limitation. I did promise one, right there in the title, after all.
UPDATE
foo
, (SELECT
bar.id
, bar.baz
FROM
foo
, bar
WHERE
foo.id=bar.id
AND foo.baz IS NULL
LIMIT
1000
) tmp
SET
foo.baz=tmp.baz
WHERE
foo.id=tmp.id
;
Some important notes:
- The update conditions (foo.baz IS NULL) go inside the subquery, along with the LIMIT.
- We have to match ids twice – once for the subquery, and once against the created temporary table. That’s why we make sure we SELECT both the id and baz from bar in the subquery.
- There’s no conditionals (other than id match) on the outside WHERE condition, since we’ve done them all in the subquery.
- MySQL also has a limitation of not allowing you to UPDATE while SELECTing from the same table in a subquery. Notice that this sneakily avoids it by only SELECTing from the other table.
So, how about that? You can now do limited multi-table updates.
Oh, except for one. Minor. Problem.
This doesn’t work with temp tables (eg if foo was created with a CREATE TEMPORARY TABLE statement).
Bugger.
However, here’s a sneaky way around that limitation too.
First of all, give your temp table another column, in the example below “ref_no INT”.
Make sure you have an index on the id, otherwise it’ll be dog slow.
Then do this:
# do this in chunks of 1k
SET @counter = 1;REPEAT
UPDATE
tmp_foo
SET
ref_no=@counter
WHERE
ref_no=0
AND baz IS NULL
LIMIT
1000
;
COMMIT;UPDATE
tmp_foo
, bar
SET
tmp_foo.baz=bar.baz
WHERE
tmp_foo.ref_no=@counter
AND tmp_foo.id=bar.id
;
COMMIT;SET @counter = @counter + 1;
UNTIL (SELECT COUNT(id) FROM tmp_foo WHERE ref_no=0 AND baz IS NULL) = 0
END REPEAT;
Some important notes:
- We’re basically flagging a thousand rows at a time, then matching only against those rows – pretty simple concept really.
- The commits are in there because MySQL can be a bit weird about not propagating changes to the database if you don’t commit inside your stored proc. This ensures that updates are passed out, which also means I can run multiple copies of this stored proc concurrently with moderate safety (if I replace @counter with a suitably large RAND() value) – well, as much as you can normally expect with MySQL anyway.
- If you want to reuse the temp table (say, to update something else from – a reverse update to that shown above) you’ll need to reset all the ref_no’s to 0.
- Whatever conditions are in the initial WHERE need to be mirrored in the final SELECT COUNT.
- Obviously just drop the table when you’re finished.
As a bonus, I’ve found this is actually quicker than doing one single large scale update. Why? Less memory is used.
So look at that. TWO ways to get multi-table updates with a limit. Nifty.
related
25.Jan.2012Find non-commented Python lines in Komodo
I’ve been doing a lot of large scale refactoring recently.
This entails a lot of “find all instances of this and replace it with that” – in non-trivial ways (of course – any monkey can do a search & replace).
Obviously I also want to only bother with non-commented lines of code.
I use Komodo for my Python coding, and while it’s a great IDE in a lot of ways, it would appear I’m the first coder that’s ever wanted to search only active lines of code (/sarcasm). Komodo does have a great regex search feature though, so I put that to use.
After much head scratching (every regex engine has its own delightful little quirks) I found this incantation:
^\s*[^#\n]*find.*$
Which will find all single-line non-commented instances of ‘find’.
Now, bugger typing that mess in every time I want to find something, so here’s a better way.
Go View | Toolbox (so the toolbox appears on the right hand side). Then right-click & “Add New Macro”. Give it a sensible name and enter this into the main text area:
if (komodo.view) {komodo.view.setFocus();}
var search = ko.interpolate.interpolateStrings(‘%ask:SearchFor:’);
Find_FindAllInMacro(window, 0, ‘^\\s*[^#\\n]*’ + search + ‘.*$’, 2, 0, false, false);
It has to be Javascript – Komodo doesn’t offer the %ask functionality in Python macro scripting (nice one, guys).
Next give it a decent key-binding on the second tab. Click in the “New Key Sequence” box and hit a vulcan key combo that works for you – I’ve used Ctrl-Alt-F – followed by clicking Add.
Hit OK & you’re ready to roll. Anytime you want to find non-commented lines of code, hit your key combo, type your search string and voila!
related
17.Sep.2011New Twitter Minimaliser
Twitter recently forced everybody over onto what they’ve dubbed “New Twitter.”
It’s got more functionality than the old version – which translates to “a lot more visual clutter.”
I’d been avoiding it for the most part, simply because I like clean, simple, straightforward. When I’m using Twitter on the web, I want to read tweets and send tweets. Nothing else.
Now I have no choice (if I’m using web-based Twitter), I thought I’d do something about it.
Thus, I present to you! The New Twitter Minimaliser.
This is a GreaseMonkey script, which means it works if you have the GreaseMonkey Add-on (follow that to get it) for Firefox, or if you run Chrome (where a lot of GreaseMonkey scripts run natively).
The New Twitter Minimaliser does the following:
Removes:
- Recommended Users
- Trends
- User Recommendations
- The “Witty Definition”
- Ability to do new style RTs (one click & all done)
Adds:
- Old Style RT button (where you quote the user & add your comment)
It also shrinks the dashboard on the side, and makes the main text area much larger. Ie, focusing the screen real estate on where it’s most useful.
It doesn’t screw with any of the code on the page (just the css) so it can’t add any new bugs. It’s also carefully optimised so it works very well on 1024×768 screens.
Oddly, now I’ve been running this script for a while, I actually prefer New Twitter to the old version. It’s much cleaner & snappier. Functionality wise it’s a bit of a wash – some things are easier, some things are harder.
Now, if I could just figure out how to get New Twitter to show me incoming DMs only (like old Twitter did, rather than one mushed up list), I’d be a super happy camper.
related
08.Nov.2009Firefox 3.5.5 screwy characters appearing
There’s something that’s bugged me ever since I upgraded to Firefox 3. Certain pages that used to work perfectly in Firefox 2 suddenly didn’t.
Instead there would be a mess on the page – lots of square boxes the size of characters with text inside them. Like this ![]() or maybe this
or maybe this ![]()
Typically this would be some kind of character encoding issue ( the server/browser specifying/requesting UTF-8 instead of ISO-8859-1 etc), or having Auto-Detect universal set off in Firefox – and most sites around the net propose this as a solution (oh, & also recommend partial reinstalls of your O/S).
Uhh, no.
It’s actually a compression issue.
If you’re having this problem, the resolution is this:
Enter into the address bar
about:config
in the Filter textbox below, type
network.http.accept-encoding
You can also just start typing “accept-encoding” until it appears on the screen.
Double click the network.http.accept-encoding entry.
Now, on my browser, it was set to
gzip,deflate;q=0.9,compress;q=0.7
but should have been
gzip,deflate
So, type that into the box & hit OK, then restart your browser (just make sure you close all your windows too)
Voila, you can now surf the web without having to constantly switch back to IE.
related
23.Oct.2009Twitter OAuth Invalid Signature on friendships/create
This is a public service announcement.
I’ve been doing a bunch of work with Twitter recently & came across this problem.
When trying to do a friendships/create, I get back “OAuth Invalid Signature.”
I’m using Tweetsharp v0.15 preview (an excellent product, btw), but I don’t think this is a Tweetsharp issue, it’s a Twitter issue. People are really scratching their heads about it.
The Tweetsharp guys proposed a solution here, but that didn’t help me. In fact, the more I googled, the more erroneous solutions I found.
Here’s my setup. TwitCleaner (the app) has a consumer keys & secret. It would then get an access token/secret for the user, & use that token/secret to make the user follow @TheTwitCleaner. This is done so we can DM the user when their report is done. We encourage people to unfollow again (if they want to) once they get their report DM.
Anyway, pretty simple. We have valid OAuth token/secret from the user, so that’s not a problem.
We’re just trying to make the user follow @TheTwitCleaner, should be simple, right? No.
I wasted several hours on this. Among the solutions proposed (& wrong) were:
- You can’t use a consumer key/secret to follow the user those keys are associated with (ie, TwitCleaner the app has key/secret, but it’s associated with @TheTwitCleaner the Twitter account)
- The OAuth information is incorrect
- The request had to be made over https, not http (not something I have control over with TweetSharp, as far as I can tell)
- That because I was passing in Client information when making the request, that was gumming things up.
Well guess what? It was none of those.
Know what fixed it?
Passing in the username to follow in lower case.
I kid you not.
Now, @TheTwitCleaner is in Twitter with that combination of upper/lower case, so I was passing it exactly as stored. But no, apparently befriend (Twitter API friendships/create) needs lower case in order to work reliably.
So now you know. Hope that saves you some pain.
related
16.Dec.2008A Nifty Non-Replacing Selection Algorithm
Algorithms are awesome fun, so I was super pleased when my little bro asked me to help him with a toy problem he had.
The description is this: It’s a secret santa chooser. A group of people, where each person has to be matched up with one other person, but not themselves.
He’s setup an array that has an id for each person.
His initial shot was something like this (pseudo, obviously):
foreach $array as $key => $subarr {
do {
// $count is set to count($array)
$var = rand(0, $count)
} while $var != $key and $var isn't already assigned
$array[$key][$assign] = $var
}
Initially he was mostly concerned that rand would get called a lot of times (it’s inefficient in the language he’s using).
However, there’s a ton of neat (non-obvious) problems with this algorithm:
- By the time we’re trying to match the last person, we’ll be calling rand (on average) N-1 times
- As a result, it’s inefficient as hell ( O(3N+1)/2)? )
- There is a small chance that on the last call we’ll actually lock – since we won’t have a non-dupe to match with
- Not obvious above, but he also considered recreating the array on every iteration of the loop *wince*
Add to this some interesting aspects of the language – immutable arrays (ie, there’s no inbuilt linked lists, so you can’t del from the middle of an array/list) & it becomes an interesting problem.
The key trick was to have two arrays:
One, 2-dimensional array (first dim holding keys, second the matches)
and one 1-dimensional array (which will only hold keys, in order).
Let’s call the first one “$list” and the second “$valid”.
The trick is this – $valid holds a list of all remaining valid keys, in the first N positions of the array, where initially N = $valid length. Both $list & $valid are initially loaded with all keys, in order.
So, to pick a valid key, we just select $valid[rand(N)] and make sure it’s not equal to the key we’re assigning to.
Then, we do two things:
- Swap the item at position rand(N) (which we just selected) with the Nth item in the $valid array, &
- Decrement N ($key_to_process).
This has the neat effect of ensuring that the item we just selected is always at position N+1. So, next time we rand(N), since N is now one smaller, we can be sure it’s impossible to re-select the just selected item.
Put another way, by the time we finish, $valid will still hold all the keys, just in reverse order that we selected them.
It also means we don’t have to do any array creation. There’s still a 1/N chance that we’ll self-select of course, but there’s no simple way of avoiding that.
Note that below we don’t do the swap (since really, why bother with two extra lines of code?) we simply ensure that position rand(N) (ie, $key_no) now holds the key we didn’t select – ie, the one that is just off the top of the selectable area.
Oh, and in this rand implementation rand(0, N) includes both 0 AND N (most only go 0->N-1 inclusive).
$valid = array_keys($list);
$key_to_process = count($valid) - 1;
do {
$key_no = rand(0, $key_to_process);
if ($key_to_process != $valid[$key_no]) {
$list[$key_to_process][2] = $valid[$key_no];
$valid[$key_no] = $valid[$key_to_process];
$key_to_process--;
}
# deal with the horrid edge case where the last
# $list key is equal to the last available
# $valid key
if ($key_to_process == 0 and $valid[0] == 0) {
$key_no = rand(1, count($list) - 1);
$list[0][2] = $key_no;
$list[$key_no][2] = 0;
$key_to_process--;
}
} while ($key_to_process >= 0);
Without the edge-case code, this results in a super fast, nice slick little 10 or so line algorithm (depending on how/if you count {}’s :)
Elegant, I dig it.
related
16.Sep.2008The Trouble With Ratios
Ratios are used all over the place. No huge surprise there – they are, after all, just one number divided by another.
The well known problem case is when the denominator (the bottom bit) is zero, or very near zero. However, there are other subtler issues to consider.
Here’s a chart that has a ratio as the X axis:
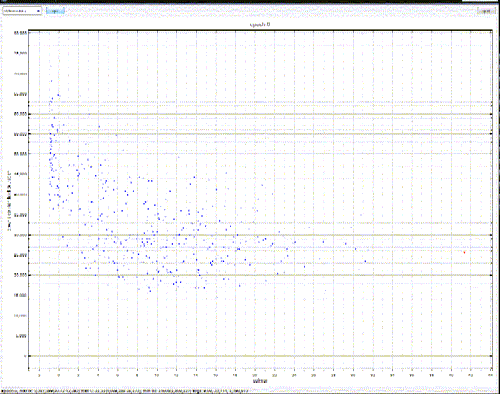
Don’t sweat the details, they’re not terribly important – just the rough distribution.
The X axis in this case is what’s called a Calmar – ie, the total dollar return of a system divided by it’s maximum drawdown. Or, in English – how much you make proportional to how big your pockets need to be. This gives a non-dollar based (ie, “pure”) number that can then be compared across markets, systems, products, whatever.
This graph is actually a bit trickier than that, since there’s actually 3 dimensions of data there – it’s just the third dimension isn’t plotted – but we’ll get back to that.
Where this gets ugly is when, in the case of the Calmar above, the drawdown drops to, or near to, zero. For example, if you have a system that only trades once – and it’s a winning trade – the calmar will be very, very large. Even if you chuck out systems that are obviously a bit nutty like that, you can still end up with situations where the ratio has just blown out of all proportion.
Which results in this:
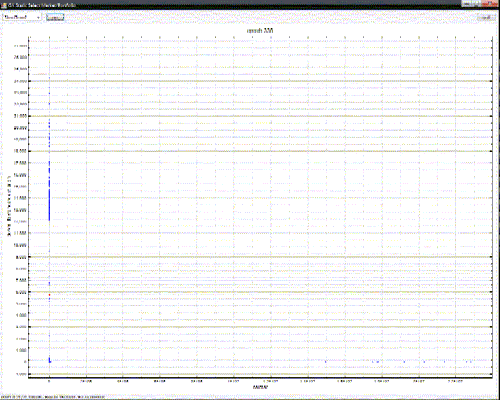
See how everything is in a vertical line on the left?
Well, it’s not. Those points are actually quite well spread out – it’s just that instead of the X axis going from 0->50 as in the first case, it now goes from 0->22 million – of which only a small number are greater than a hundred (you can see them spread out on the right, very close to the Y axis)
In this example, we can see the problem, so we’re aware of it. However, what if the ratio had been the unplotted third dimension? We might never have known.
Now, the way that I’m using these ratios internally, I’m protected from these sorts of blowouts – I simply compare sets of ratios. If one is bigger, it doesn’t matter if it’s bigger by 2 or by 2 billion.
However, there are many situations where you might want proportional representation. If one value is twice as big, say, it should occur twice as often. In this case, ratios that explode out by orders of magnitudes quickly swamp results, and drive the whole thing into the ground.
You swiftly end up with a monoculture. One result eats all the others, and instead of a room full of happy spiders doing their thing, you end up with one fat angry spider in the middle of the room. Umm, so to speak.
Ratios can be dangerous, kids. Watch out!
related
02.Jul.2008Unit Testing – Necessary, but Not Enough
I realised recently that I’d hit a point of diminishing returns. My overall code base was now so complex that any change I introduced in certain areas was taking exponentially longer to debug & ensure accuracy.
Of course, I had a test rig – otherwise how would I know what I was doing was correct in the first place?
The central core of all my systems is a rebuild of a now antiquated black box trading platform. I don’t have the source, but I need to duplicate the behaviour.
The test rig is pretty sophisticated – it didn’t start that way, and it shouldn’t really have needed to be, buuuuut
The old system:
1. Calculates using single precision floating point math.
If I need to explain why this is painful, check this out – if even the guys running Excel get occasionally tripped up by floating point math, what hope is there for the rest of us? Single point means there’s only half as many bits (32) to do maths in vs the default double (64 bits). Rough shorthand, single precision gives you get 6 decimal places. A number like ‘12000.25’, you’ll lose the ‘5’. If it’s negative, you’ll lose the ‘.25’. This means lots of rounding errors, and the more calculations you do, the more errors. The systems I’m working with do a LOT of calculations.
2. Rounds incoming numbers non deterministically
Mostly you can guess correctly what it’s going to decide a market price becomes, but particularly with markets that move in 1/32’s or 1/64 (ie, not simple decimals), this rounding becomes arbitrary if not damn ornery (rounded? no. up? no. down? no. truncated? no. based on equivalent string length? maybe)
3. Makes ‘interesting’ assumptions
Things like the order that prices get hit, how numbers are calculated internally (eg X = function(A/B) often returns a different result from Y = A/B; X = function(Y), that slippage only occurs in some situations and not others, and so on. Some make sense, in a way, many we don’t want. So now we have two modes of operation “old, broken, compatible, testable” and “new, not-broken, different numbers, untestable”
4. Has ‘chains’ of internal dependencies.
So, unsurprisingly, any of the above errors will then cascade through the output, fundamentally changing large chunks of the results.
So, the test rig allows for all this. Understands where common rounding problems occur, and how they cascade. Sorts by seriousness of the discrepencies, and so forth. Oh, and it does this by automatically tracking 60 or 70 internal variables for each calculation set across 7000 days on 60 markets. Ie, filtering & matching its way through 20-30 million data points.
But this still isn’t enough.
And this is where I see the light, and realise that this unit testing stuff that people have been raving about might actually be useful. So far, it has been. It’s enabled me to auto-scan a ton of possible problems, keep things in alignment as the system adjusts to changing requirements – all the palava you’ve read about.
But I’ve been thinking. No amount of unit testing would catch the errors my test rig will. Not that the rig is that amazing – just that they’re operating at fundamentally different levels. Unit testing won’t tell me:
a) If I’ve made a mistake in my logic
b) If I understand the problem space correctly
c) If my implementation is correct (in the “are these answers right?” sense)
d) If I understand the problems space <b>thoroughly</b> (obscure, hard-to-find & subtle edge cases are very common)
e) If my unit tests are reliable & complete – have they caught everything?
Unfortunately, thinking about this more, I’m not convinced that even unit testing PLUS my test rigs (yes, rigs. I lied before. I actually have two, no three, that grill the system from subtly different angles) are going to catch everything.
Of course, it’s a game of diminishing returns. How much time do I spend testing vs actually delivering resuilts?
Shifting to a higher level language helps – fewer lines of code = fewer bugs. It’s still a stop gap though. Programs are only getting larger & more complex.
Better architecture always helps of course – lower coupling = fewer cascading problems across sub-domains, but when we’re juggling tens, hundreds, or thousands of subsystems in a larger overall system?
I’m not convinced there’s an easy answer. And as software gets more complex, I only see the overall problem spiralling at some high power of that complexity. No matter how clever our test rigs, how well covered in tests our code is.. How do we move forward efficiently without getting bogged down in “Can we trust the results?”?
Right now, I just don’t know.