Some Swype Tips
I first saw Swype (the funky text entry system) on a friend’s Android phone several years ago. So, you can imagine how eagerly I awaited it on iOS, and my excitement when it finally arrived. I’d estimate it at roughly three times faster than the built in iOS keyboard (which itself is something of a technical marvel).
Needless to say, while Swype truly is great, it still has a few rough edges. However, with some judicious googling, moderate experimentation and a lot of hunting through forums, I’ve found a few hidden gems that makes using it a LOT less painful.
(because keys aren’t hit one after another, I’ll describe Swype motions with hyphens. Eg, Swyping cat would be c-a-t – ie, you start at c, then swipe your finger up to a, then across to t)
Handy Shortcuts
- comma-space gives you a comma followed by a space
- fullstop-space gives you a full stop followed by a space
- l-space gives you “
- x-space or z-space gives you !
- m-space gives you ?
- You can swipe directly from the 123 button to any of the keys on that second key layout (all the numbers and common non-alpha characters) without having to change from normal entry mode
Swype key(the ‘S’, bottom left)-gear icon takes you to options. From here you can see your personal dictionary, and delete items (by swiping left) if you want to get rid of them. You can also change the colour of the keyboard, etc.
The REAL best secret tip
Most useful though? If you click-and-hold on a word on the word bar (the list of words that appears just above the keyboard), you can delete words from the dictionary. This includes words in THEIR dictionary, not just your own. This is BRILLIANT.
The reason this is so helpful? Because so often we’ll end up accidentally dragging across words we didn’t intend. And there are some REALLY dopey words in there that are very close to common ones. Eg, Bachmann (as in Michelle Bachmann, American right wing banana) instead of Banana. Abutting is right next to Anything. Luge disrupts my attempts at Life. Etc. So, when you find a silly word appearing, pause, swipe the same word a few times until you see the stupid word in the wordbar, then press and hold and you’ll delete it. Voila, it’ll never pop up again.
Other stupid words are things like “m.p.h”, so anytime you swipe m-. instead of .-space (both VERY close to each other) you get “m.p.h” instead of “. ” *SIGH* I spent WEEKS manually backspacing “m.p.h” until I learned about the word delete trick. Since then, ahh, I’ve probably saved myself from having to delete it 15-20 times a day. Excellent.
I’ve also found that deleting names (proper nouns) I know I’m never going to need (I can always type them in manually if I ever do use them) – eg I would always get Erik, instead of With – made a huge difference in terms of how often incorrect words appeared.
By the time you’ve deleted 20-30 of your common mis-swypes (and they vary from person to person – all our hands are different sizes, etc), you’ll find that the keyboard works very noticeably better.
related
The Importance Of Pipes
There’s a very subtle, often overlooked thing in Unix, the pipeline, or | character (often just called a pipe).
This is perhaps the most important thing in the entire operating system, with the possible exception of the “everything is a file” concept.
In case you’re unfamiliar (or didn’t feel like reading the wiki page above), here’s the basic concept:
A pipe allows you to link the output of one program to the input of another.
eg foo | bar – this takes the output from foo, and feeds whatever-it-is into bar – rather than, say, having to point bar at a specific file to make it do anything useful.
Why are pipes so awesome?
Well, the following reasons:
- Each program only has to do one thing, & do it well
- As such, development of those programs can be split up – even to the point where a thousand people can independently write a thousand programs, & they’ll all still be useful
- Each of those programs is very simple, thus faster to develop, easier to debug, etc
- Extremely complex behaviour can be created by linking different programs together in different ways
- None of that higher level behaviour has to be pre-thought or designed for
So, Unix has ended up with a ton of small but powerful programs. For example:
- ls – lists a directory
- cat – displays stuff
- sort – sorts stuff
- grep – finds things in stuff
- tr – translates stuff (eg, upper to lower case)
- wc – counts words or lines
- less – pauses stuff, allowing forwards & backwards scrolling
I’ve been deliberately vague with the descriptions. Why? Because ‘stuff’ can mean a file – if we specify it, or, it can mean whatever we pass in by putting a pipe in front of it.
So here’s an example. The file we’ll use is /usr/share/dict/words – ie, the dictionary.
cat /usr/share/dict/words
displays the dictionary
cat /usr/share/dict/words | grep eft
displays dict, but only shows words with ‘eft’ in them
cat /usr/share/dict/words | grep eft | sort
displays ‘eft’ words, sorted
cat /usr/share/dict/words | grep eft | sort | less
displays sorted ‘eft’ words, but paused so we can see what the hell we’ve got before it scrolls madly off the screen
cat /usr/share/dict/words | grep eft | grep -ve ‘^[A-Z]’ | sort | less
displays paused sorted ‘eft’ words, but removes any that start with capital letters (ie, all the Proper Nouns)
cat /usr/share/dict/words | grep eft | grep -ve ‘^[A-Z]’ | wc -l
gives us the count of how many non proper-noun ‘eft’ words there are in the dictionary (in the huge british english dictionary? 149, since I know you’re curious)
So there’s an additional benefit which is probably obvious. Debugging a complex set of interactions with pipes is incredibly straightforward. You can simply build up what you think you need, experimenting a little at each stage, & viewing the output. When it looks like what you want, you just remove the output-to-screen, and voila!
For the end-users, this means that the operating cost of using the system in a complex manner is drastically reduced.
What would happen without pipes? You’d end up with monolithic programs for every imaginable combination of user need. Ie, an unmitigated disaster. You can see elements of this in, umm, ‘certain other’ operating systems. *cough*
Most importantly of all, there is a meta benefit. A combination of all of the above benefits.
Pipes enable incredibly complex higher level behaviours to emerge without being designed in. It’s a spontaneous emergent behaviour of the system. There’s no onus on the system development programmers to be demi-gods, all they need to do is tackle one simple problem at a time – display a file, sort a file, and so on. The system as a whole benefits exponentially from every small piece of added functionality, as pipes then enable them to be used in every possible permutation.
It’s as if an anthill full of differently talented ants was suddenly building space ships.
Perhaps a better bits-vs-atoms metaphor is of money. Specifically the exchange of goods (atoms) for money, allows the conversion of those atoms into other atoms, via money. In the same way, pipes allows different programs to seamlessly interact via streamed data, in infinitely variable ways.
You don’t need to know how to make a car, since you can do what you’re good at, get paid, & exchange that money for a car. Or a boat. Or a computer. Society as a whole is vastly better off as each person can specialize & everybody benefits. Think how basic our world would be if we only had things that everybody knew how to build or do. Same thing with computers & pipes.
What seems like an almost ridiculously simple concept, pipes, has allowed an unimaginably sophisticated system to emerge from simple, relatively easily built pieces.
It’s not quite the holy grail of systems design, but it’s bloody close.
related
16.Dec.2008A Nifty Non-Replacing Selection Algorithm
Algorithms are awesome fun, so I was super pleased when my little bro asked me to help him with a toy problem he had.
The description is this: It’s a secret santa chooser. A group of people, where each person has to be matched up with one other person, but not themselves.
He’s setup an array that has an id for each person.
His initial shot was something like this (pseudo, obviously):
foreach $array as $key => $subarr {
do {
// $count is set to count($array)
$var = rand(0, $count)
} while $var != $key and $var isn't already assigned
$array[$key][$assign] = $var
}
Initially he was mostly concerned that rand would get called a lot of times (it’s inefficient in the language he’s using).
However, there’s a ton of neat (non-obvious) problems with this algorithm:
- By the time we’re trying to match the last person, we’ll be calling rand (on average) N-1 times
- As a result, it’s inefficient as hell ( O(3N+1)/2)? )
- There is a small chance that on the last call we’ll actually lock – since we won’t have a non-dupe to match with
- Not obvious above, but he also considered recreating the array on every iteration of the loop *wince*
Add to this some interesting aspects of the language – immutable arrays (ie, there’s no inbuilt linked lists, so you can’t del from the middle of an array/list) & it becomes an interesting problem.
The key trick was to have two arrays:
One, 2-dimensional array (first dim holding keys, second the matches)
and one 1-dimensional array (which will only hold keys, in order).
Let’s call the first one “$list” and the second “$valid”.
The trick is this – $valid holds a list of all remaining valid keys, in the first N positions of the array, where initially N = $valid length. Both $list & $valid are initially loaded with all keys, in order.
So, to pick a valid key, we just select $valid[rand(N)] and make sure it’s not equal to the key we’re assigning to.
Then, we do two things:
- Swap the item at position rand(N) (which we just selected) with the Nth item in the $valid array, &
- Decrement N ($key_to_process).
This has the neat effect of ensuring that the item we just selected is always at position N+1. So, next time we rand(N), since N is now one smaller, we can be sure it’s impossible to re-select the just selected item.
Put another way, by the time we finish, $valid will still hold all the keys, just in reverse order that we selected them.
It also means we don’t have to do any array creation. There’s still a 1/N chance that we’ll self-select of course, but there’s no simple way of avoiding that.
Note that below we don’t do the swap (since really, why bother with two extra lines of code?) we simply ensure that position rand(N) (ie, $key_no) now holds the key we didn’t select – ie, the one that is just off the top of the selectable area.
Oh, and in this rand implementation rand(0, N) includes both 0 AND N (most only go 0->N-1 inclusive).
$valid = array_keys($list);
$key_to_process = count($valid) - 1;
do {
$key_no = rand(0, $key_to_process);
if ($key_to_process != $valid[$key_no]) {
$list[$key_to_process][2] = $valid[$key_no];
$valid[$key_no] = $valid[$key_to_process];
$key_to_process--;
}
# deal with the horrid edge case where the last
# $list key is equal to the last available
# $valid key
if ($key_to_process == 0 and $valid[0] == 0) {
$key_no = rand(1, count($list) - 1);
$list[0][2] = $key_no;
$list[$key_no][2] = 0;
$key_to_process--;
}
} while ($key_to_process >= 0);
Without the edge-case code, this results in a super fast, nice slick little 10 or so line algorithm (depending on how/if you count {}’s :)
Elegant, I dig it.
related
02.Aug.2008Cuil Really Isn’t (Yet)
There’s been a lot of grumping about Cuil lately, so I thought I’d add to it (hopefully in interesting new ways).
I’ll talk in context of a site that I have *cough* some familiarity with: galadarling.com (hint: I built & managed it for the last two years). This site gets over 100k uniques a week, has a google pagerank of 6, and a technorati rank in the mid 5000’s. I.e., it’s not Yahoo, but it is a significant, popular smaller site.
The obvious test – surely searching for gala darling would return the site? It’s not complicated. Her name is the url. But no:
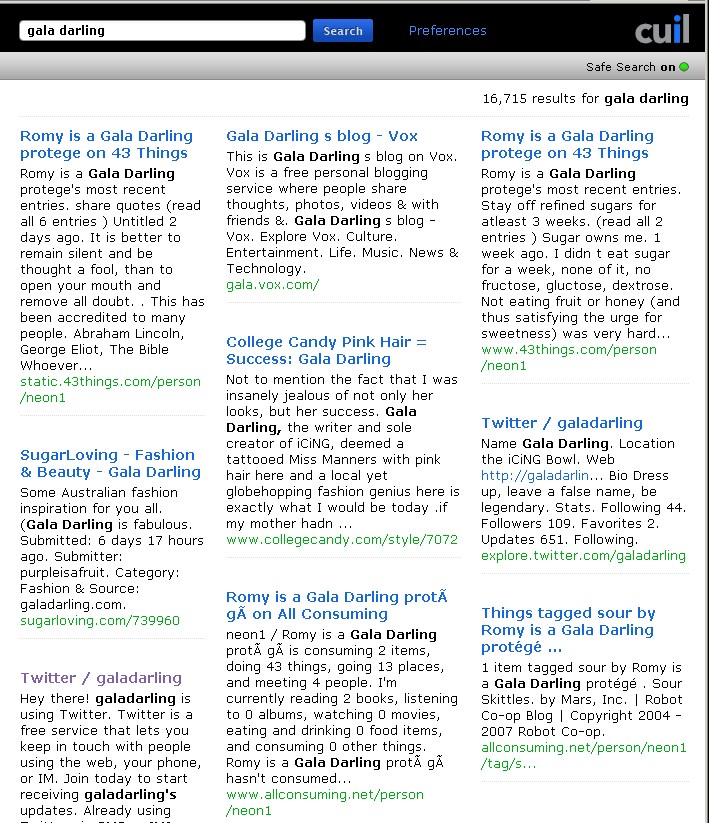 (click for a clearer view)
(click for a clearer view)Maybe it’s the safe search? No, flick that off, and exactly the same results:
 (click for a clearer view)
(click for a clearer view)Putting in “gala darling” in quotes (just like that) results in the exact same result set. Huh?
Even scarier, putting in galadarling (all one word) doesn’t even return the site. How is this possible?
Even worse than that – gala.vox.com is the second returned result. This is a single page that was setup once and then ignored. It’s not just not finding the correct result, it’s actively returning junk.
None of these sets include Gala’s livejournal, which is updated every couple of weeks, let alone the actual site that has her name on it.
With the exception of her twitter account, all the results on the front page are other sites, talking about her… and this is useful.. how?
I looked at the first 20 pages of results – couldn’t find either her livejournal or main site. vox.com somehow managed to get several hundred mentions. A single collegecandy page appeared at least 5 times.
Ok, it’s common knowledge that the Cuil results are crap. How about some other things.
- When you first load the page, you have to actually click to get into the textbox to enter your search terms.
- For some reason I’m asked to accept cookies both from cuil.com (fair enough), and cuilimg.com (what? why?)
- When paging through the results, there’s no way to go back to the start, as once you get past page 10, the earlier pages scroll off to the left, so you have to go backwards in chunks of 4 or 5.
- There’s no way to get more results on a screen. Even on my 1900 pixel wide screen & a tiny font, I still only get 10ish results per page. Google allows me 100 – why should I click-wait-click-wait just to use Cuil?
To their credit, Cuil’s bot is not hitting the site anywhere near as much as it used to, so that’s one good thing. Considering galadarling is updated typically once a day, plus maybe a hundred comments, the Cuil bot (twiceler) used to hit the site about a thousand times a day (resulting in it getting blocked by damn near everyone). For comparison, Google’s bots hit it 400 times a day (partly that will be because there is context-sensitive advertising on the site, so Google needs to scan for that). Now Twiceler is visiting about a hundred times a day – much more reasonable given the update frequency.
I’ve talked to the guys running Cuil (back when it still had two ‘l’s in its name). They’re obviously very smart cookies and they definitely care about what they do. If they can shake Google up – well, great – and I say that as a Google shareholder. They definitely have a lot of bugs to iron out though, and the reliability of those results needs to be right at the top of the list. Without trust, what do they have?